
You’re harming other people with data - you just don’t know it
Hot gAI startups and "weaponization of data" by all of us, against all of us, and to our benefit of us.


I’m Sven writing this to help you build things with data. Whether you’re a data PM, inside a data startup, internal data lead, or investing in data companies, this is for you.
Let’s dive in!
Some gems are inside the gAI startup batch; NfX identified many.
Data is being used as a weapon all the time.
by all of us
against all of us
and to our benefit
(1) Hot gAI Startups
What: The VC firm NfX, a VC firm focused on network effect-centric startups in the seed stage, published this list of hot gAI startups. They infuse their investment perspective into it and, in particular, look into early companies. This makes the list different from others you might see around the web.
My take: It also makes the list more helpful than you see on the web. Generative AI-based startups fall into two camps:
The ones that know what they are doing and invest heavily in science-driven innovative products around generative AI.
Those with no clue that build the next ChatGPT wrapper.

The companies on this list tend to fall into the first camp.
“Instead, these are the companies indicative of the next generation. The ones with notable momentum. The hot ones worth following.” (NfX hot 75 gAI startup list)
A few great examples of this I have looked into before are Pinecone, LangChain, and Outerbounds. Pinecone builds a vector database, in itself a complex technological challenge. LangChain offers an open-source framework for working with language models like ChatGPT. It helps you to chunk up your document to build your own embeddings on top of ChatGPT and many other tasks necessary to integrate any general language model into a specific tool.
Finally, my personal underdog favorite outerbounds builds metaflow, ML, and AI infrastructure for everyone.
All of them build science-infused heavy products. Not a ChatGPT wrapper.
(2) You’re harming people with data

{kind=link}
Once a super lawyer in Gotham City, Harvey Dent turns into Two-Face, a supervillain obsessed with the number two. Two-Face obsessively makes all important decisions by flipping a two-headed coin, with the other half scarred.
Killing someone or not? Two-Face flips a coin. Throw him into the shark tank or lion pit? Two-Face flips a coin. Coins themselves carry no evil; they carry little meaning themselves. They are just a piece of metal. Two-Face infuses them with evil.
Regarding data, everyone is a bit like Two-Face: every individual, every company (yes, also the “Don’t be evil” Google), and every country.
Isolated data in itself has little meaning and little value. It’s us that turn the data into something else. We flip it, and 50% of the time, it comes up as something that harms other people or companies to our benefit.
We’re doing it intentionally and unintentionally. Companies use data as a business tactic to harm competitors, and sometimes customers, and countries use data as a military tool.
But this isn’t about judging. This is about making you aware of it. You should be aware of two facts: (1) you are using data, and this is a lot of time at the expanse of others (unintentionally) (2) others are doing the same thing to you.
You should be aware of two facts: (1) you are using data, and this is a lot of time at the expanse of others (unintentionally) (2) others are doing the same thing to you.
Let me explain by calling on Jondou Chen…
(3) Weaponization of data
What: Jondou Chen gave a conference talk in 2015 and wrote it up in this article. The talk focuses on weaponized data in the nonprofit & public sectors.
My take: If you strike the word “nonprofit,” this article reads like a business article from today. And that’s a sad and dangerous perspective.
We all believe that more data is good, and it is, but I think we got the wrong picture in mind here; we keep the “data is oil” picture; you have more, and you make more money.
But I like the image of electricity more.
Having none of it sucks; having lots of it is excellent for all humanity. But it also brings the dangers of handling it, of getting little children electrocuted on power sockets.
Chen identifies six challenges with data that lead to the weaponization of it - they show why people can get electrocuted by data; let’s go through four of them (although I find them all to be very relevant!):

The illusion of objectivity
“I need numbers to show that the website relaunch succeeded.” Ever said such a thing? If so, you were trying to weaponize data (unconsciously, I assume!).
Whenever you try to find data after something happened, with a given outcome in mind, “website relaunch succeeded,” you’re enforcing a selection bias and only looking for data that shows your outcome. You can always find such data by selecting wisely.
But this data in this context is only harmful. It harms you because it only confirms your outcome; it doesn’t let you get to the actual question, “Did the website relaunch succeed?” (which you could ask after the relaunch) or “How does a successful website relaunch look like?” (which you need to ask before the relaunch).
It harms other people because once you show off this data, your claim “website relaunch succeeded” gains the illusion of objectivity through data.

The delusion of validity
Even if you were to ask yourself before the website relaunch, “How will a successful website relaunch look like?” you might still realize: Setting up a reasonable hypothesis and tracking it is hard!
So you might end up going for easy-to-measure things instead of going with what you really think is a successful website relaunch.
Again, you present these numbers and harm yourself and others by deluding everyone into the validity of the hypothesis-number relationship.
The focus on technical over adaptive: Our machine learning systems need data, vast amounts of data. So machine learners take the data they got. Sometimes they will start initiatives to collect more data, but they work with what they got.
It’s the technically available data that is used, not the one we would wish for.
It’s the data that is technically available that is used.
This isn’t a wrong choice, but it misleads us into thinking it is the only choice and that the outcome is the best we can get.
It was like that in the consumer credit industry in the 1990s. At that time, every bank was issuing credit cards with a uniform pricing model for one reason: the only data they had was debt default rates and the willingness to pay for credit cards on average.
Banks at that time thought uniform pricing was the best they could do because of the technically available data.
But one bank thought differently: Signet Bank. Led by two visionary consultants, Fairbank and Morris, they invested in years of data gathering, varying pricing, variations of offerings, of experiments of all sorts until this tiny little bank became Capital One, one of the largest consumer credit companies in the USA - by investing in adaptive data, into the data that needed to be collected, not the available one.
Fairbank and Morris realized the focus on technically available data was hurting rather than helping. Available data turned into a weapon that was hurting every consumer credit company.
The illusion of generalizability
The data orchestrator company dagster wrote an article about tracking fake stars on GitHub.
It turns out startups do that. Some companies buy fake stars on GitHub. Why? Because the GitHub recommendation algorithms assume generalizability.
Some companies buy fake stars on GitHub. Why? Because the GitHub recommendation algorithms assume generalizability.
Startups are stepping into a grey area here, using the fact that GitHub algorithms assume generalizability and buy tons of fake stars at the expense of both the company GitHub as well as the users of GitHub.
But if you look closely at the article, then you notice the company dagster itself is weaponizing data inside of it. They post a “Results” section at the end that displays like this:
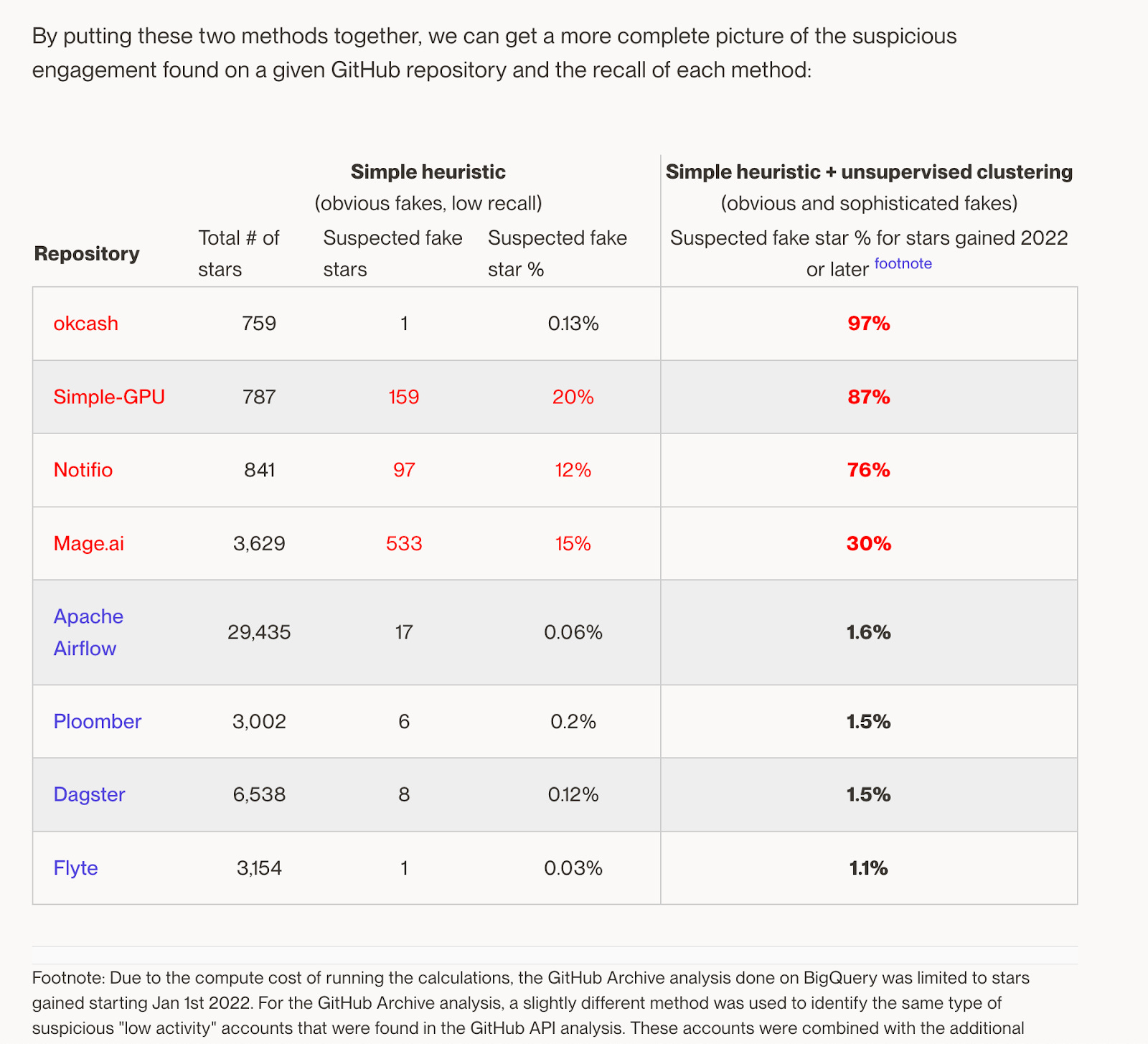
This suggests that four companies are super engaged in buying fake GitHub stars. In comparison, four other companies (including Dagster) are extremely truthful regarding GitHub stars - of course, somewhere, there is a note/ disclaimer explaining the considerable selection bias in this setup. It’s likely, this is not intentional, but it is using the illusion of objectivity of data that makes us believe in the objectivity of this ranking.
Be aware
Be aware you’re weaponizing data often. Be aware companies, as well as other people, are using data to your detriment often.
I suggest you skim over all of the paragraphs of the article because every single headline is becoming more accurate by the minute.
Companies need to be aware this is happening. In business, weaponized data can turn into business tactics, or it can turn into unethical behavior. That’s up to you. Deweaponizing, as shown in the CaptialOne example, can make you and your company better off.
There are no boundaries here. It’s up to you to flip the coin and navigate this space.
How was it?
Until next week,
Sven