
What is Surgical Fine-Tuning and Why You Should Care
Another Deep Learning Breakthrough: Surgical Fine-Tuning, Modeling data better with an entity-centric approach, How to easily estimate ML projects


This is the Three Data Point Thursday making your business smarter with data & AI.
Let’s dive in!
Another Deep Learning Breakthrough: Surgical Fine-Tuning
Modeling data better with an entity-centric approach
How to easily estimate ML projects
Want to share anything with us? Hit me up on Twitter @sbalnojan or LinkedIn.
Another Deep Learning Breakthrough
WTF is surgical fine-tuning?
TL;DR: Surgical fine-tuning makes an ML algorithm relevant to your specific business context faster & better through precision changes.
That’s an advancement over regular fine-tuning.
Fine-tuning: take any general-purpose ML model (ChatGPT, Image things,...). Then give it your data set to learn your "kinks"”
It's like a baking recipe...
If you go from cake => muffins, you basically only need to change the last two steps.
If you go from cake to bread, you change the first few steps.
You don't need to tear up the whole recipe each time.

Fine-tuning = tearing up the recipe, keeping some parts in mind, and writing a new one.
Fine-tuning with frozen layers = exchanging just the last two steps, whether you’re baking muffins or bread
Surgical fine-tuning = deciding what to exchange first, then exchanging stuff.
Let’s get into the details…
In ML fine-tuning, you take a big fat generic model, your particular training data, and then either:
Present it to all layers of the model.
Or a subset (rest is "frozen"), usually only to the "ending" of the model
BUT: Fine-tuning, in general, sucks.
Generic models are trained on massive datasets; you don't have massive datasets to teach them all your kinks. That's why "frozen" layers are pretty cool.
But what's even better is to freeze layers based on each batch you provide, given HOW your batch differs from the ML model's training set.
That’s (now) called surgical fine-tuning.
The new key challenge with surgical fine-tuning (unsolved!)?
Knowing how inputs differ
Knowing what layers of ML models actually do...
There’s an excellent research paper on this. Note, this is new and pretty much-untested stuff (the paper just does a small qualitative test).

To us, this still sounds like a game-changer in fine-tuning.
So what? As always, don’t implement this stuff yourself. Wait for some tech to become available, making this work on any model. And right now, there is no tech at all for this.
But for founders/entrepreneurs/PMs, this might be a huge opportunity!
How anyone can model data better
The art of data modeling is a lost art.
Modeling is the interface between humans and data; it's the linchpin in most companies.
And in most companies, it's a very fragile, tiny linchpin.
Maxime Beauchemin, creator of Airflow and Superset, has been trying to reinvent modeling for almost 6 years now.
And now he has found a framing that sounds mainstreamable: Entity-centric data modeling.
The idea is pretty simple: Marry ML feature engineering with data engineering and you got yourself the new and modern art of data modeling.
So how does it work, and what’s the big deal?
TL:DR; Here’s an infographic explaining it with examples

So what? No matter who you are, you should adopt this. Try it out and notice how much smoother it makes your data operations run.
How to Estimate efforts for ML projects
ML projects or features always seem like a daunting big thing to you?
They don’t need to, in our opinion.
The good news is you can estimate the order of magnitude using two basic questions:
The Cost of Delay (CoD): Does it hurt a lot or a little when the system is down?
Does the algorithm need to work in real time or not?
The key: Think about the algorithm, not the “display.” The display will serve stale results if the algorithm is down, and it will not be able to react to recent things if it’s not real-time.
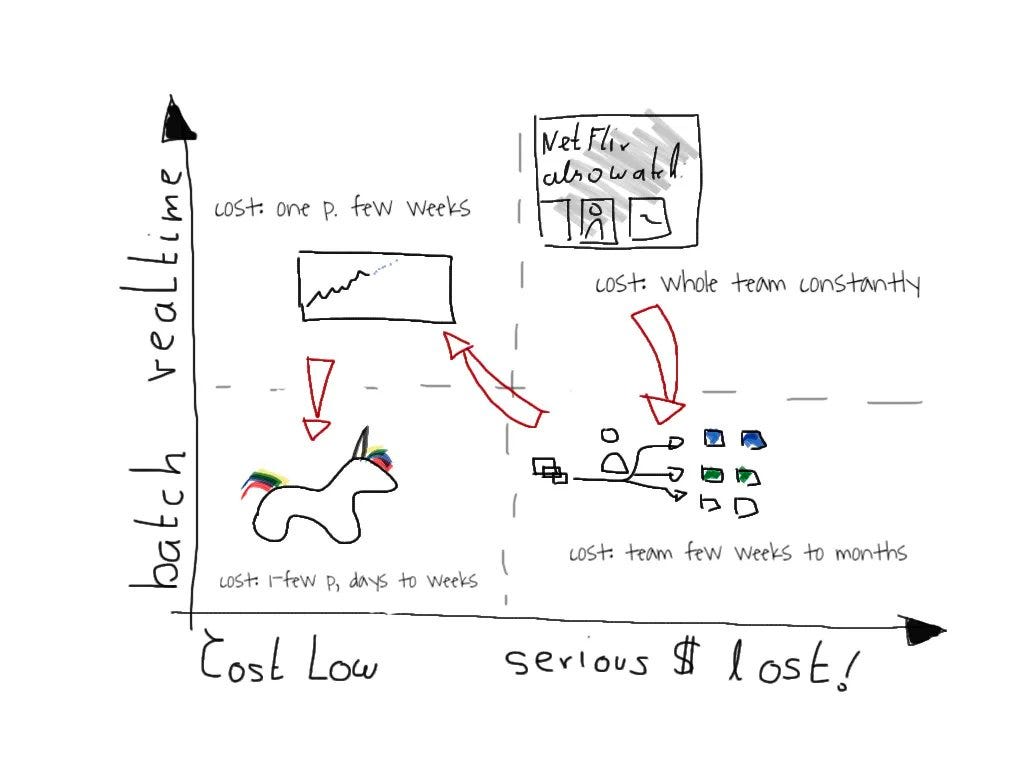
The steps in detail:
1) What does it cost if the system goes down? If the algorithm serves stale results?
If your “what other people watched” CSV list that updates every 24 hours doesn’t get updated daily, do you lose a lot of money?
Probably not.
But what about your CEO’s real-time prediction system? Mmmmh.
2/ Do you need a batch process or a real-time system to create new predictions on the fly?
Hint: You need "just" batch more often than you think.
3/ Now it's simple
RT + high CoD >>batch + high CoD >> RT + low CoD >> batch + low CoD
batch + low CoD is likely a week or less for one person, then double or triple for each level up.