
Way of The Water: Identifying Data Unicorn Potential; Thoughtful Friday #24
A map of the data space helping you to identify (1) potential data unicorn start-ups (2) new super-growth product ideas (3) ways to pivot into one.

I’m Sven and I’m writing this to help you (1) build excellent data companies, (2) build great data-heavy products, (3) become a high-performance data team & (4) build great things with open source.
Every other Friday, I share deeper rough thoughts on the data world.
Shameless plugs: Check out Data Mesh in Action (co-author, book) and Build a Small Dockerized Data Mesh (author, liveProject in Python).
Let’s dive in!
Data grows exponentially, but that growth is unequally distributed.
You can make great choices and position yourself 10x better than competitors to capture this growth.
Hex.tech choses to position itself way better than hyperquery, focusing on decentralised data usage over just data analysis sharing.
NextData is positioned from the start to become a data unicorn, right inside “fast moving waters” from day one (as James currier would put it).
🔮🔮🔮🔮🔮🔮🔮🔮🔮🔮🔮🔮🔮🔮🔮🔮🔮
Companies like hex.tech have something, they seem to pick up speed, like being carried by “fast waters”. Let’s take a look at why.
In “Find the Fast Moving Water”, by James Currier @ NfX, James writes about how important finding great markets or market segments are if you want to found or fund a company, or create a new product that will take off like a rocket ship.
But what James is referring to is not “product market fit”, you find that in all kinds of waters, it is the kinds of great market segments, that if you find product market fit there, will carry you much faster than other parts of the market.
I think for the data space, we can make this more concrete. I usually use two “maps” to find “fast waters” that work only for the data world. And today,I want to share one of them, it’s called the DAKS-framework.
The gist of fast moving water.
The idea of fast moving water is simple, you find product-market-fit in all kinds of waters. Fast moving waters is the place where the market is moving fast, and growing fast, taking you with it.
Growth in data isn’t equally distributed.
Data is growing exponentially, the value of data for a given company is growing just as fast, so all you have to do is to pick any kind of data related product and you’re off right? Wrong. Growth in data isn’t equally distributed. It happens along four dimensions.
These four dimensions are
the decentralization of data usage as well as its creation.
The amount of data, that is the sheer exponential growing amount of data every company has available today, and double that in 2 years or so.
The kinds of data, because in a couple of years, 95% of data will be event-based, real-time, non-flat (as in images, videos, “unstructured”).
And snowflaky, sitting in 100s of different systems that want to be linked up and integrated into each other into a long pipeline.
These four dimensions form the D-A-K-S framework.
A product can focus on each of these dimensions in isolation. It can also focus on 2-3. Ideally a product takes into account 3-4 of these dimensions.
Any tracking solution is first and foremost focused on collecting data from decentralised sourcing. If these tracking results then get pushed into different tools, like e.g. Segment does, the product fulfils the “D” of D-A-K-S.
Products like Fivetran only take into account the sourcing side, without the usage side, so they do not fulfil the “D”. But Fivetran as a data movement tool focuses on moving all different kinds of data (K) as well as on integrating complex data stacks (S). Making it a “KS” product.

It’s not a map to the gold pot at the end of the rainbow, it is a map to find “fast waters”.
To be clear, this map doesn’t mean everything inside the center is a pot full of gold. Argo.AI just shut down even though it is positioned firmly inside the center.
It’s a map to find fast moving waters, places where the action gets real! Places where, if you can hold on to the water, your company and product will move quickly, almost carried on by the currents.
Companies like Databricks and Snowflake are there, right at the center, taking into account almost all of these dimensions in very different ways.
Companies like Confluent & Starburst or Gong are at the verge of moving into these areas.
Into fast moving waters.
The map applied.
To understand the map a bit better, I like to look at the two data companies hyperquery and hex.tech.
Both essentially are building a notebook-based product. Hyperquery focuses on sharing data analysis whereas Hex focuses not on data analysis but on building knowledge by building “data apps”.
(1) I would place the company hyperquery at the edge of the (K) quadrant. They are trying to work with more and more kinds of data, but truth be told, they aren’t focusing yet on the important sets that will dominate the data sectors in a couple of years.
(2) Hex on the other hand is positioned clearly somewhere on the (D) spectrum, moving up along those borders of these quadrants into the intersection by focusing on building data apps and exposing them to actual data users, not just “sharing analyses with a handful of people”.
Hex is also deeper into the (K) by supporting Python cells together with SQL cells, making it easier to work with arbitrary data.
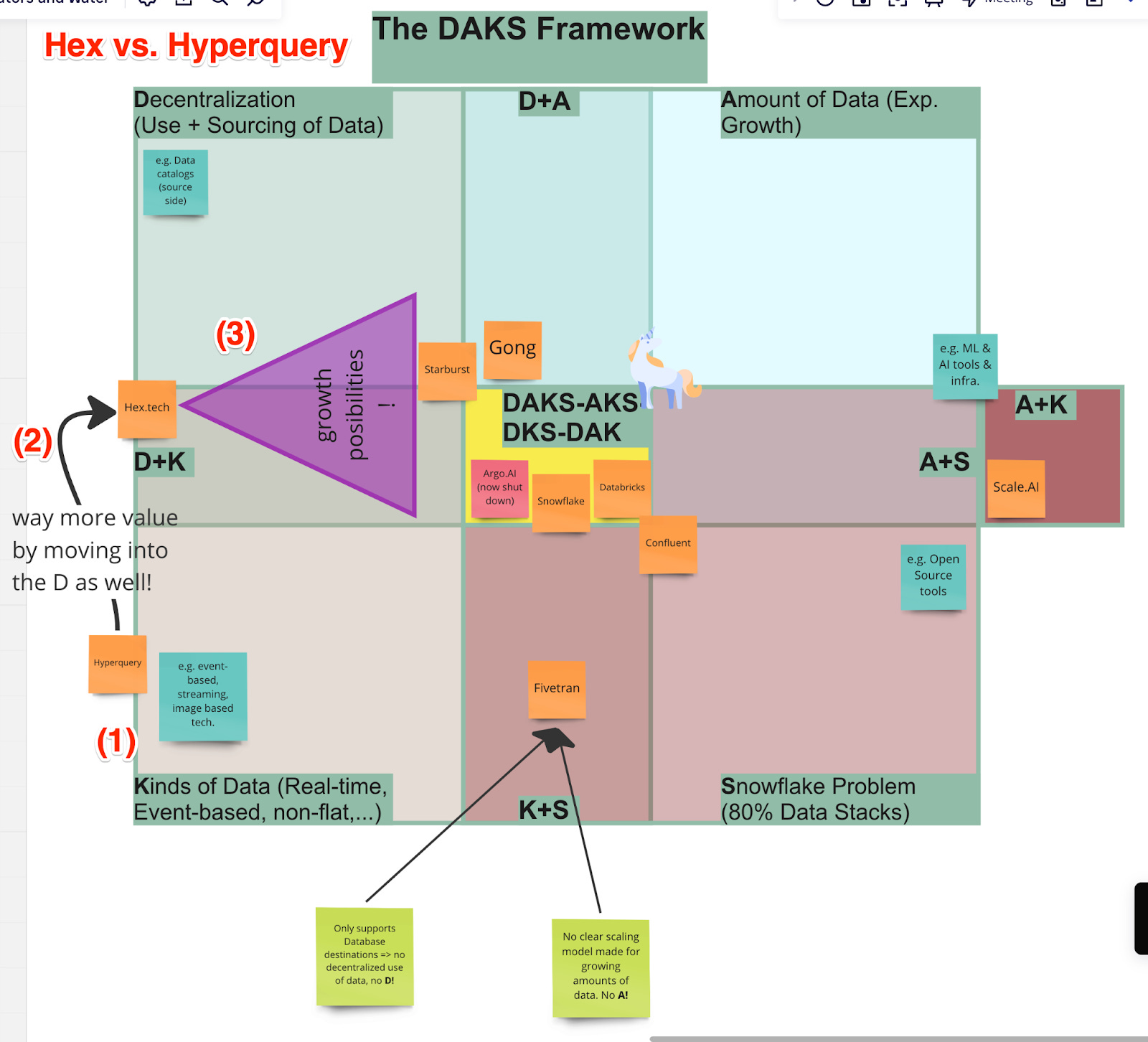
(3) But, there are huge growth opportunities for both companies (indicated by the funnel). Hex could go all in on the (D) decentralised ideas by integrating the “data apps” into third party tools either by partnering with someone in that sector or by building the integrations themselves.
Hex already has Python support, by adding data lake connections it would be able to move smoothly deep into the (K) quadrant.
The start-up nextData, and its founder Zhamak Dehghani chose their spot well; they are already right in the middle of the D+K quadrant, positioned even better than Hex. And that at launch.

So it is possible to choose great, from the very beginning.
Note: The NextData OS product might already be positioned right in the center of this framework, I haven’t taken a deeper look at it yet.
You can move there as well.
While databricks & Snowflake certainly took their time to slowly move into the middle of this map, it doesn’t mean you have to start on the edge as well.
Unequally distributed growth means just that, you can make smart choices to pick your parts of the map. You can start off better or worse. You can pivot and move into faster moving waters.
Remember slow moving waters feel “just fine” as well, you will find product-market fit there just as you will in fast moving waters. You just won’t become a unicorn. And unicorns are awesome.