
Thoughtful Friday #8: 10 Things Every Data PM Should Stop Doing


The ishango bone is one of the earliest counting sticks found on earth. The use of that 25,000-year-old, 10 cm long piece of bone with equal distant markings on it is disputed.
But whatever the reasoning behind using it, counting sticks, in general, wasn’t invented to be pretty. They were invented to count, and then to use that count to make decisions and take an action. Be that the good old split counting stick which is used to count debt levels in medieval Europe, or possibly the ishanbo bone.
I feel that exact perspective on the only and sole purpose of data can speed up insights into the data product discovery process. Using just one perspective: The only reason to even store data is to turn it into better/faster decisions for actions.

Picture courtesy of the Mathematical Association of America.
Svens Thoughts
If you only have 30 seconds to spare, here is what I would consider actionable insights for investors, data leaders, and data company founders.
- Data has just one purpose. The only purpose of even looking or storing data is to turn it into decisions for better/faster actions. Period.
- Data has always been used for that. Our brains do just that all day long. Turning sensory inputs (data) into decisions for actions.
- The Datacisions Cycle illustrates how data is turned into actions. Data is created somewhere => collected => turned into information => into insights => into decisions => into actions which then create new data.
- This value perspective reveals the need for data & bottleneck analysis. If this framework applies to your situation, then there is a long pipeline of steps involved in creating actual value (better/faster actions). Thus, hard numbers on every step and a bottleneck analysis become the focal point of your product management.
- Improvement outside the bottleneck is worth exactly 0 $$$. The bottleneck is still the bottleneck, just with more “inventory” piling up.
If the core of your product is about data, then I consider you a data product manager. It doesn’t matter whether you’re managing an internal team of analysts and data engineers, whether it is a crossfunctional machine learning engineering team, or whether you’re the head of product for a shiny new data start-up. You work on what I consider data product management for the sake of this piece.
First, let’s talk about the missing piece value, and how to understand that deeper using the datacisions cycle. Then let’s look at the ten things you should stop doing!
Note: Yes this is mostly a rant, but I hope like my last one, it’s insightful. Sorry for that! I personally consider process (of product discovery) & execution to be the number one critical skill to master for a (data) product manager. All of the things mentioned below would likely be the output of a good product discovery process anyways, but for me, this particular value perspective is a bit of a shortcut, maybe a compass. Hope it helps you too.
The Missing Piece: Value
I feel like the data space is overflowing with tech. But that often casts a shade over the actual question: the value. A shade that I don’t see that often on the software side of things.
In data-heavy products, in my humble opinion, there is really only one good perspective to take on, when thinking about the value of a product and that is in terms of decisions.
The product analysts’ job is to help the product manager make better/faster/more high-quality decisions about the product.
The recommendation system inside YouTube is trying to get me to decide to watch another video, optimized for the minutes I watch.
The churn rate system used by a sales department helps the salespeople decide which customers to focus on.
LinkedIn DataHub, a data catalog, is there to help people find & understand data sets better, so they can more quickly find the right data, and then make decisions based on that.
Notebook tools like Noteable.io or Hex.tech also are there to increase the speed at which decisions can be made inside companies.
Datacisions Cycle: How Data turns Into Decisions
The figure below is the datacisions cycle. It has five distinct stages, Actions which create Data, data which is collected and turned into Information, form which we derive Insights which turn into Decisions which then yield Actions that create Data.
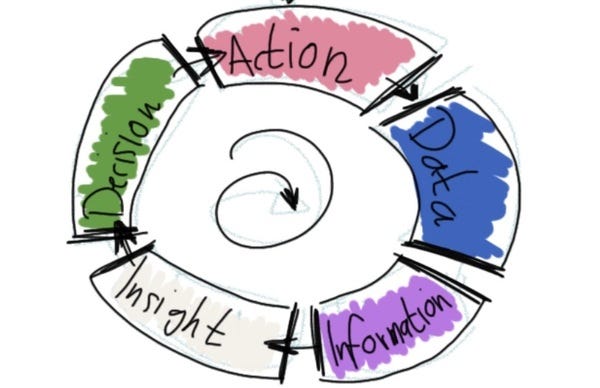
Netflix recommender is a data product in the sense I described it above. I personally do the following process when I decide I wanna watch something on Netflix (and FWIW, Netflix realizes that this is already one dimension in and emails me stuff so I know from the start that I wanna go there, and not to Amazon Prime,…):
1. I log into Netflix,
2. I browse stuff, possibly search some, figure out something I wanna see based on the data I see. This data has been turned into information for me in form of “top 10 watched” etc. lists.
3. This information is usually enough for me to generate an insight (ah yes, this seems good)
4. And make the decision to start the movie,
5. I do so which generates more data.
Ok, the key insight in most recommendation engines is the following: The bottleneck is NOT in the availability of data. It’s in the information/insight => decision stage. I can read lists of movies all day long, what is missing are the pieces of information & the insights I need to decide which one I want to see. In that sense, recommendation engines yield tremendous value, because in my datacisions cycle for movie selections, there is a bottleneck right there, and nowhere else.
Numbers and bottlenecks are everything
That’s exactly the point, the bottleneck. Would it be beneficial to add more data to the movies? Probably not, because I am already overwhelmed with the number of movies that are there. I am totally fine with getting a few recommendations and getting some piece of information that helps me get the insight (the explanation why this is good!) that I truly watch this movie. The line “because you watched Brave” usually does the trick…
Some time ago, I want to build a recommendation system for e-mails with some cool and simple machine learning to start of. The idea was very similar, information overload should produce a bottleneck. But turned out I was wrong. When I ran the numbers along this cycle, doing a rough estimate of the conversation rates here and there, and included the subscription base we had at that time, I realized I had no chance in hell to ever make a buck on that.
My personal lesson: Always fill in the datacisions cycle, find the bottleneck and run the numbers.
Data is always turned into action
There is one big difference between data products and software products: If your website is missing the “buy” button, people cannot buy. But if the digitized data is not there, people will still make decisions!
Data, even crappy and incomplete ones is turned into decisions all day long. That’s what our brains do. So this is always happening. You’re only making an existing thing better! You’re never on “fresh ground”, there’s always an alternative. The value is not in “providing data” it might be in “providing more data”, or data in a structured form, and only then if this additional data doesn’t hit a bottleneck downstream.
My personal lesson: Always consider the alternative, because there always is one.
—-
With these basic lessons about value in mind, let’s take at our 8 stops & starts.
1. Stop Storing, Start Using
I remember a time when we started to do a major update for one of our products, the internal business intelligence system. The company just shifted towards a new set of APIs which provided lots of new information. So we decided to build a new infrastructure to pull data from these APIs and then provide them through our business intelligence system to end-users. We planned on providing the new data in parallel to the old-world data.
We worked full-time on the new infrastructure for 2 months to store this new kind of data and then started to transform and provide the data to end-users.
The problem? After months of work, we realized, people liked the new data but didn’t use it to make decisions. Because, as it turned out, they didn’t need this new kind of data at all. The same information was inside the old data and they continued to use that to make their decisions. I had mistaken data for information & insights.
The solution? Stop to think just in the “data storing” phase of the datacisions cycle. There is no value in stored data unless there is a clear (even if it’s in the very distant future) path to using this data to make decisions.
Start to focus on the use of data, and start there, work your way back.
If you run any kind of company and think about opening up the data for the end-users, think about how this would help them make better decisions. What kind of information do they really need to make better decisions? If you start there, you will end up with much shorter delivery times and less waste.
2. Stop Incremental, Start The Whole Cycle
I am a fan of working incrementally. But it has to be done right.
10 years ago I worked together with my cofounder on a start-up in the business intelligence space. We wanted to provide vacation rental data to vacation rental homeowners, help them set prices, decide whether to build a pool and the like.
The idea was to scrape the big portals like Airbnb, booking.com, etc. on a regular basis to get loads and loads of data. Then we would combine that into information with correlations and possibly even some kind of tips & hints based on your specific vacation rental home offering.
After a couple of months, we had a first set of data ready, and then we had a fundamental debate. Should we provide this data in forms of a “data product” just as it is? Like huge lists of average prices in specific regions and so on? Do one small increment? Or should we continue to work, transform the data into correlations, tips & hints and then provide that to the end-users as our “first increment”?
I remember me arguing for the quick and first increment. And now I am pretty sure I was wrong. Just providing the data might be a smaller increment, but we would’ve will very likely be able to come up with an MVP that would’ve used less data, non-automated data, but already contained correlations, hints & tips that would’ve enabled people to make decisions.
The problem? Cutting increments as parts of the datacisions cycle will divert you from your actual goal.
The solution? Cutting increments as hole “slices of the cycle” going all the way into the decision.
3. Stop to Focus, Start to See the Alternative
Let’s take a look at Bob. Bob manages an internal data team. Alan is from the operations department and asks Bob to create “a regular list of all orders which aren’t shipped yet with lots of extra information”.
Bob asks Alan why he needs that. “Oh, it’s to call up the suppliers and get them to ship stuff. If things don’t arrive, it’s becoming really expensive for us.”
Sounds like a good thing right? Since Bobs’ team needs to pull in some new data, he estimates it will take a week to complete this…
Until Bob asks the right question “Wait, but right now you’re doing nothing at all to stop that?”
“Oh yes we do,” Alan replies, “but our intern is doing that in excel, and you’d save him like 4 hours each week if you automate that”.
And just like that, a value estimation of “serious problem for our company” drops to “4 hours of saved work/week”. So start to understand the alternative, or make a huge mistake in estimating the value.
The problem? Decisions are always based on data, that’s what our brain does, it turns sensory inputs into outputs. If you do not consider that decisions are always made, you will think the value of the decision is equal to the value of data. It is not.
The solution? Go deep and understand how the decisions you’re looking at are made. If Amazon wouldn’t have a recommendation system, how would people make their buying decisions? Obviously, they do, probably based on other comparison pages, written content, etc. So the value of the recommendation system is not, that people buy more, but that they buy “a little bit more and very specific things from Amazon”.
4. Stop Building Predictions Alone, Focus on Explainability
One time, we’ve built a machine learning prototype that was predicting HiPo (high potential) customers. We thought it was a great thing to provide that to our sales department so they could then realize that potential.
But I remember when we presented this to several salespeople in feedback rounds, their feedback was universal and simple: “Yes, these are HiPos, but why do you think that? If you told me why your fancy algorithm, marks these customers, I could’ve excluded 90% from that list right away”
The problem? Our predictions were good, but we forgot (again) to think till the end, where the sales rep has to take that and decide which customers to focus on. We forgot to walk the complete cycle and provide the information that was needed to produce insight, the explainability.
The solution? We used some random machine learning explainability algorithms to describe why customers were selected. Once we did that though, we realized we could’ve gotten away with a bunch of much simpler ranking algorithms without any fancy machine learning. So stop focusing on building fancy and super accurate predictions, start to focus on providing information that is needed to derive insights from your “predictions” (may they be as simple as a ranked list).
5. Stop “Updating Technology X”, Start “Increasing Data Quality”
Let’s take a quick look at Bob again. He’s running this internal data team. His team tells him “we should really update to technology X.1, stuff will keep on crashing otherwise”.
After a moment of consideration, Bob takes a step back and asks his team “so what are the benefits of this update to technology X.1?”. “Well, things run faster, less crashes, more logs,…”
Bob pauses, “But what about the end-user? Will he have any benefit at all?”
After a long pause, the team says “Eh, not directly. But we will be able to fix things faster!”
Now we’re getting somewhere, Bob thinks. “How much faster?”
“Well, we had around 10 crashes this year, and we usually spend a day searching logs, and another fixing it. With this update, we should be able to do that in 2 hours”.
There you go. Bob thinks. So if I take this datacisions cycle concept, it means, my end users will be able to have data up and running again within 2 hours instead of in 2 days. And my team can spend the time to work on more important things. So now Bob has a grasp on the value of this update.
The problem? Technology is not part of the datacisions cycle, not in a generic way at least. If you forget to ask yourself why you’re doing an update or exchanging a piece of technology, the technology will become the main part of the conversation. And you will likely choose the wrong part. If Bob were to now ask his team “team, how can we make sure we get our data up and running within 2 hours”, I bet the team will actually be able to come up with 5 more ways of making that work which is not an update.
The solution? Stop considering technology as part of the user experience. Start to think about the capabilities of the technology as parts of the user experience.
But what if you’re building the next data tool? Then you surely need to focus on technology right? Even there it seems a lot of teams out there still are inspired by the datacisions cycle…
6. Stop Focusing on Technology, Start Focusing on Bottlenecks
When the company Airbyte soft-launched its software for moving data, it had two connectors. The two connectors (one of them was S3) connect to a data source and pull the data into some other place. A year later, they had over 200 connectors, which is more than most of the decade-old competitors in the space.
Clearly, they focused on growing the number of connectors, which seems like growing technology adoptions. But if you take a look at the datacisions cycle, they were applying all of their energy on just one step, going from data creation => to data storage.
They realized that there is a huge market segment where this is the bottleneck in the datacisions cycle. These are companies that have working mechanisms on the rest of the datacisions cycles, companies that are already to a certain degree data-driven. Their sole bottleneck is to move stuff around quickly, then combining things together & making data-based decisions isn’t a problem for them.
On the other hand, if you look at the company Meltano, the picture looks different. The company started out focusing on connectors and moving data, but today the roadmap is full of integrations to “great expectations” and in general “plugins”. Meltano chose to focus on a slightly different market segment, one where the problem is not connecting to the source but also in extracting information & insights from the data. One where it is necessary to easily control the quality of the data.
I think it’s easy to conflate the two approaches. But in truth, they focus on very different market segments in terms of the company profile & their state of the datacisions cycle.
The problem? Looking through the technology lens always puts value aside. Even if you know your current customer base really wants the integration to Snowflake, the question remains, does it help their companies make better decisions? (It probably does, but sometimes it doesn’t!)
The solution? Start with the datacisions cycle first, think about every technology choice you have what does it do to decisions? For whom does it enable quicker decisions?
Another Example: The company Atlan made a very conscious decision in this direction to focus on companies using Snowflake in the beginning. That cuts off a huge part of the market segment, but it also accesses one, which has certain characteristics alongside the datacisions cycle. These are companies willing to pay for speeding up analysis which means they are very likely already deriving lots of analyses from their data. But that means, they are also a good pick for a data collaboration space, which thrives on loads of analyses, not just data.
7. Stop Starting with the Data, Start Starting With The Graphics
My team built an internal tracking product. It allows development teams to easily track some key interactions (you can read a bit about it here: “How Mercateo is Rolling Out a Modern Data Platform”). These things were important on the business side, but development teams had a hard time tracking such things before we launched our internal tracking product.
When I pitched the idea to developers, I included their experience, code, and data.
…. Now that did not work out too well. I quickly realized I need to tell the whole story and start at the end. So instead of showing code & data, I showed mocked graphics, a mocked GUI for the internal tracking product.
Seeing this, developers and end-users alike got the idea, loved it and we went on to build it.
The problem? Too often, when seeing data, we get stuck at that stage, the data stage, we might progress into the “information” stage, but information usually also looks like a plain table of rows and columns. It’s hard to get excited about rows & columns, and it is hard to imagine what kind of impact these rows & columns could have.
The solution? My suggestion is to start at the end, mock the GUI, even if you do not plan on building one (we did not); Then build the GUI first, with very minimal data. Get the final thing into the hands of end-users, and by the “final thing” I mean the thing that has the potential of giving them insights for decisions.
8. Stop Pricing for Volume, Start Pricing for Insights
I feel like one of the key insights of the company Snowflake was to consider the datacisions cycle in their pricing strategy.
Every other datastore at that time was basically “size prized”, meaning the amount of data you could store and the computing power was coupled together, and you paid one price tag for the package. You paid 2,000$ for the 5TB Postgres with 64GB RAM basically.
Snowflake decided to decouple this, you could pay 300-600$ for anywhere between 1-10TB of storage, and scale up your RAM as you wanted (basically), not tied to the storage size.
This is a very important improvement from the datacisions cycle perspective. The first perspective prices for data storage, and it tied to that. But if your company doesn’t have a bottleneck there, well, then you will pay a pretty big overhead just to increase the computing power.
The computing power needed on the other hand is tied directly to the number and complexity of queries run on the data. If you have a lot of analyses and decisions you want to derive from your data, computing power is your measure of value for this product.
By decoupling these two things, Snowflake allowed people to pay for relieving the “insights/information” bottleneck ALONE, which meant they had a huge leg up in the market compared to the competitors at that time.
If you’re wondering how you can make that work, the simple (& hard) answer is probably: “choose a wise proxy measure”.
The list doesn’t really stop here, but I hope by now you got the idea.
If you’ve read this far, I am pretty sure you are also ready to leave some feedback!
This article is …
It is terrible | It’s pretty bad | average newsletter… | good content… | I love it, will forward!
Data; Business Intelligence; Machine Learning, Artificial Intelligence; Everything about what powers our future.
In order to unsubscribe, click here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue