
Thoughtful Friday #5: Build a (Data Mesh) Self-Serve Platform Step-by-Step


Let’s iteratively build a full-fledged data platform, and on the way remember, learn & apply 4 important platform-related concepts.
This kind of Thoughtful Friday is about applying four different platform frameworks to build one very specific one. If you particularly like this thought, leave feedback so I can write more of them!

Robots are awesome. These are the three iterations we’re building of our platform.
Self-serve Data Platforms are data platforms that have a self-serve character, meaning they allow data producers to “serve” data in some kind of sense. A platform in this context simply means a tool that makes things easier.
Let us continue an example I shared in an edition of Three Data Point Thursday and let us play around with some of the key concepts of self-serve data platforms. In my opinion, almost all of them actually apply to all platforms, specifically data platforms but of course, we’re looking into the self-serve character in relation to the concept of a data mesh. Nevertheless, I think this product exercise can be inspiring for anyone building any kind of platform.
Svens Thoughts
If you only have 30 seconds to spare, here is what I would consider actionable insights for investors, data leaders, and data company founders.
- There is a ton of confusion & knowledge around platforms. Knowing how frameworks work together can help you make a ton of progress & create value without getting sidetracked.
- Platform frameworks come in layers. Some apply only to very specific frameworks, while others like the architectural components apply to all of them, be it Stripe or your internal self-built chat tool.
Quick overview of the concepts we’ll use
After writing this article down, I realized it might be good to see the different concepts we apply in this case to a very specific kind of platform and see which scope they actually have. Our “self-serve data platform” is specified in the following way:
- it’s a “generic platform”, it fits the definition of any platform,
- it is a company internal platform,
- it is a platform with many “complements”, 3 or more parties we are trying to mediate between over the platform.
This allows us to use a lot of pre-existing knowledge! We can apply a bunch of platform-specific frameworks:
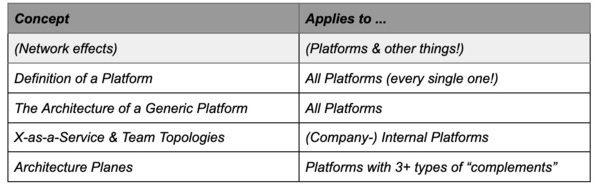
Our Minimalist Data Mesh & Self-Serve Data Platform
Let us start with the data mesh I’ve outlined in my newsletter before.
“…. I think the hardest concept of the data mesh paradigm is the platform. Let us build a super small data mesh platform, a small git repository containing CSVs.
Let’s decentralize ownership: Give every autonomous team push rights to their respective “folder” inside the git repository. So now, teams can completely autonomously push data into the data mesh.”
So basically, we have a git repository called “data” with folders:
- “data_product_1”
- “data_product_2”
- data_catalog.CSV
And so on. If we add a wiki page, or better yet a README.md we’d already have a pretty thin platform! One might say a “thinnest viable platform”. The README.md contains instructions to add a bit of information about your “data_product_X” to the “data_catalog.CSV”.
Concept 1: What is a Platform Really?
In my words, a platform mediates interactions between differing parties. Since we want to have a self-serve platform, we actually want to have not just two, but three parties.
Here are our parties:
- the data producing teams that push CSVs into folders
- the data products, the CSVs itself
- data consumers like analysts, machine learners, etc.
Our platform mediates the interaction between the data producers and their data by providing a central storage place. That’s not really much, is it? So nothing much going on for that part yet…
It does mediate the interaction between data sets and consumers by providing a central place to get data, by standardizing the format to CSV, and by providing the data catalog. That’s quite a lot there!
Finally, it does nothing for the interaction of consumers & producers. There are no communication channels in place currently.
Our key takeaways:
- we have three parties and thus three interactions
- we currently only are working on two of them, mostly focused on just one!
- this means, we’re currently only increasing value for the data consumers mostly.
That seems a bit odd, let’s make that more clear by exploring a second concept before we do one iteration on our platform…
Concept 2: What is an “X-as-a-Service”?
The Team Topologies framework is essentially about organizing tech teams to deliver the most value by aligning them with the flow (of the value stream). It features different collaboration modes, but it has one in particular which suits well for a “platform team” and here the team maintaining this platform would actually be a “platform team”.
The idea of “X-as-a-Service” is to provide a tool as a service to other teams with the sole purpose of speeding up their development.
In our example, we have a team maintaining this really minimal platform. It provides this tool to data consumers and data producers, to speed up their work. But does it really do that at the moment?
Currently, it is only speeding up value creation for the consumers, and might even put a little bit of weight onto the data producers. On the other hand, if we want to speed up value creation for the data consumers, which might be a set of analysts, going through a CSV to discover data is also probably not so handy, so there we would likely speed up value creation a lot by providing a proper data catalog…. So let us iterate on that.
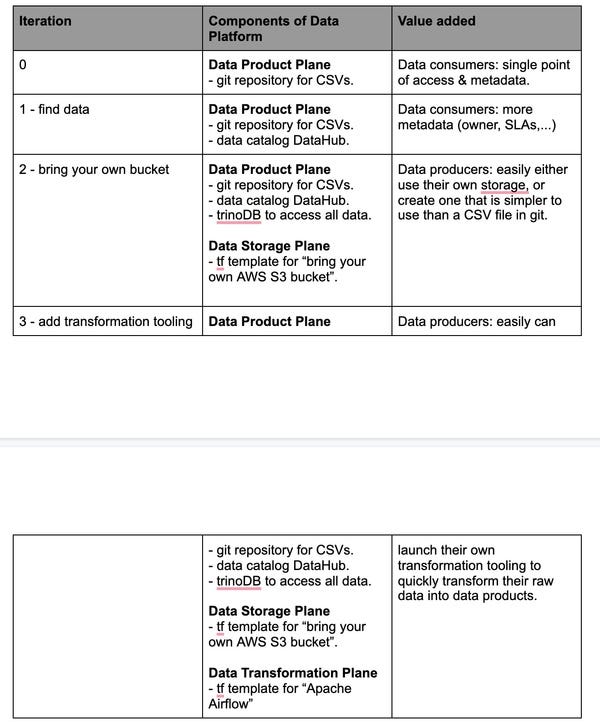
Iteration 1: Adding a Proper Data Catalog
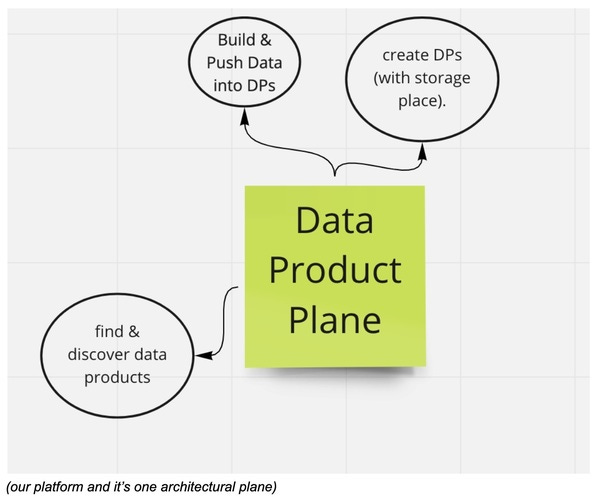
In our first iteration, we’ll add a proper data catalog, let’s use LinkedIns DataHub, it’s open-source but also there are some hosting providers so we can get started with that one quickly.
We would also make a change to the README stating that it is necessary to register the data product first in the data catalog. But we really don’t want to put more burden on the data producers, so I suggest we write a little script that is as easy to use as the process before. The script should take a JSON with the metadata and push it into the catalog AND create the folder.
Great! We hopefully just kept everything almost the same for the data producers but increased the value for the data consumers by quite a bit.
Note: But this is also the point where we probably realize that we do need a small team to maintain the self-serve platform, as we cannot ignore the SLAs that come with having a running data catalog somewhere (although using a hosted solution would put that off by a few iterations).
Now let us tackle the data producer side, as said above, it’s a platform, and if we do not make it easy for the producers to connect with data products, there simply won’t be many. For that, we can look at the idea of modularity inside the platform.
Concept 3: Modular Platforms & Architecture Planes
I’ve written a bit about how self-serve data platforms should have different architecture planes, as well as how the architectural view on any kind of platform helps to understand how to manage it, I’ll just quickly summarize the key points:
- all platforms share three fundamental architectural components, “the kernel of the platform”, “the complements - the things we connect with the platform” and “the interface of the platform”.
- the interface is supposed to stay almost completely fixed
- the kernel of the platform is used to evolve quickly
- the complements can vary over time and crosssection.
- all platforms with more than 2 complements need a much higher degree of modularity.
- a higher degree of modularity yields “architecture planes”, different bundles of features of the platform, connected through APIs as well as accessible from the outside.
In our case, we have three complements, the data consumers, the producers, and the data sets.
Currently we basically just have one architectural plane, a “data product plane”. However, as we already noticed, we now need to help data producers derive value from the platform as well. The first step could be to stop them from having to create something new to use the platform. So let us help them to “bring their own data storage” into the system, all the while keeping the interface as fixed as possible!
Iteration 2: “Bring your own bucket”
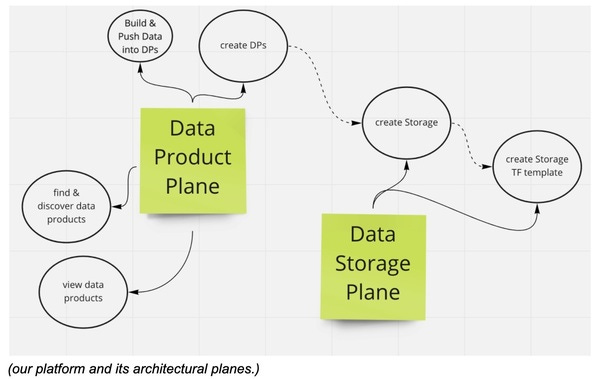
We will add a second architectural plane to our data platform, a “data storage plane”. This concept will allow anyone to:
- store the location of a data product
- get a terraform template for launching storage in the form of an AWS S3 bucket anywhere and automatically register it.
Additionally, we modify the “data product plane” internally, to use the data storage plane to store the locations. This way, we are creating optionality! Basically, we’re doing a non-breaking change to our interface, allowing:
- people who don’t have their own storage or enough terraform skills to simply use the CSV storage by default
- people with advanced knowledge if they want to use the advanced functionality.
Great! We’ve just taken a big leap for the data producers, we’ve taken a large burden away from them and this way enables many more teams of data producers to use the platform.
But wait, what about the consumers?
The Catch: Data Consumers Just Lost value!
You probably already noticed that we just made the data consumers worse off. Why? They still have one single point of truth for the metadata, the data catalog.
But they lost their single point of access, the repository.
Luckily, there is some smart technology that enables us to change that. We can use a query engine like trinoDB to access our data that is located in AWS S3, and the CSV files.
Note: …with some modifications. There is a CSV connector, but I’m not sure about its maintenance level. The easiest solution is probably to just dump the CSVs into another data store that has a well-maintained trinoDB connector.
Now, let us take this a step further, the data consumers currently have a “surplus”, they get more value than they had before the platform, whereas the data producers still only are at “roughly 0 additional value”. Let’s see what we can do to change that.
Iteration 3: Create value for the data producers
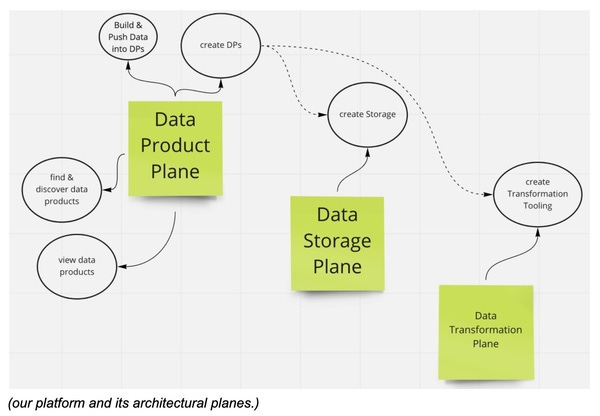
We hopefully got the idea of how we can introduce non-breaking changes, keeping the interface mostly fixed while still adding new functionality to the platform.
We also know, we want to enable the data producers to create their data products as quickly as possible, so that they can create value as fast as possible.
Data producers will typically need to:
- 1. collect “raw” data,
- 2. turn that raw data into some kind of useful information,
- 3. store that information somewhere to provide it to others.
We already started to help the data producers with (3). If we wanted to help them with (1) we could for instance help them use tools like “snowplow” or Google Analytics (or something based on the measurement protocol). But since I usually find that collecting data is actually not that hard for development teams, let us turn to (2) for this final iteration.
Turning raw data into useful information isn’t easy, it is usually referred to as “transforming data”. Good toolsets are the ones that a development team can use easily. So depending on exactly that, the development teams, might come up with something like Apache Airflow as suitable transformation tooling.
We might also provide a set of Java libraries, pre-built containers, or whatever suits the requirements of the company we’re in.
If we go with Apache Airflow, we have two options:
1. Provide the tool as a hosted service, and do the maintenance of the tool ourselves
2. Providing the teams with smart templates which easily link to the already existing parts of the platform.
Again, what you choose depends simply on what is best for the company, what enables the most flow. In our case, let us pick the smart template as it goes well with the already provided AWS S3 bucket templates.
Overview
Puh, we just did a whole lot of work I think, here’s a list to see the three iterations together…
Btw., these architectural planes could be way different. Your planes could be organized around end-user functionality and as such of course organized into consumer & producers in this case. We could also organize into “advanced data producer functionality” and “default data producer functionality” if these groups really exist in our company, we could also add a “platform maintenance” group, and so on and so on… At this stage reorganizing is still easily possible.
I hope you enjoyed this piece!
Leave feedback if you have an opinion about the newsletter! So?
It is terrible | It’s pretty bad | average newsletter… | good content… | I love it, will forward!
Data; Business Intelligence; Machine Learning, Artificial Intelligence; Everything about what powers our future.
In order to unsubscribe, click here.
If you were forwarded this newsletter and you like it, you can subscribe here.
Powered by Revue