
Starlake.ai And The One Question Every Start-Up Should Answer


This post is based on a discussion I had with Hayssam Saleh, founder & CEO of starlake.ai, an all-in-one data platform.
"We want to get rid of data engineering" is the sentence that stuck with me. Maybe not the best way to say it, but as someone with a decade of experience in the data space, I get the point: There's a gap between the data producers and the users of data.
But before we dive into this gap, let’s understand why that’s important at all
One question every start-up should be able to answer
I’m still struggling with one question for starlake.ai:
Give me an example of a company that uses this and is super stoked about it. Now tell me, why are they so stoked? How is this new approach 10 times better than what they got before? (10% doesn't get anyone "super stoked")
Given that they have a bunch of users, including big banks, moving 100s of GBs per day, I’m sure there is an answer to this question. The answer to this question is likely the wedge Hayssam is looking for. But from our conversation, I wasn’t able to tell.
But I can tell you, if you’re unable to answer this question instantly, you don’t have a product-market fit. You shouldn’t even think about working on product messaging or distribution; you need that first.
This brings us back to that one sentence, getting rid of data engineering and the gap…
The data engineering gap
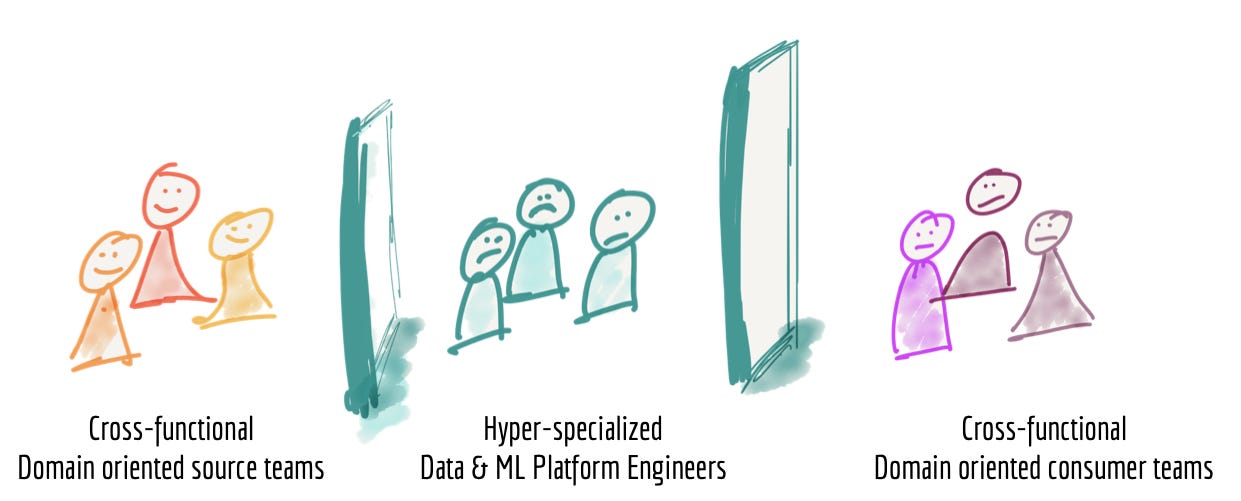
The picture was taken from Zhamak’s original data mesh article.
Ever tried to ask an analyst why the data quality seems shitty? He won’t be able to tell you because, in most companies, hyper-specialized data engineers build the pipelines. Ask the data engineer why a specific data row is the way it is, and he’s not gonna be able to answer either because he isn’t producing the data, being almost shut off from it.
That’s the great divide of data. The past 6 years seem to be a journey to fill this gap, though!
ML teams are becoming increasingly cross-functional, integrating at least two of the abovementioned groups.
Analytics Engineering has emerged as a way of trying to bridge this gap with more cross-functional manpower.
The data mesh has emerged as an effort to have completely cross-functional teams with all walls torn down.
There is a gap, and most companies feel the urge to close it in machine learning, data science, or analytics applications.
So, let’s unravel what starlake.ai tries to do from here on. I’ve talked to Hayssam, the founder and CEO, for some time about his vision, and I loved that part of it, which is yet another approach to bridging this gap.
A quick intro to starlake.ai (my words)
Hayssam has been consulting with his team for clients in the analytics space for 4 years now, deploying the solution they’ve incrementally developed over time (it’s open source.)
You bring your data warehouse + your business intelligence tool, and potentially your orchestrator, and you’re all set to go. Starlake does the ingesting of data (getting it from the source), helps you with the transformation of data (in plain SQL), and then automatically constructs a DAG for you that it schedules and runs with Airflow (integrated into starlake).
Starlake tries to abstract a lot of the nitty-gritty details of data engineering away. You don’t define an orchestration schedule, rather you simply define how fresh you want your data you want to have.
Everything works in the UI + inside git, so you get to enjoy all the benefits of CI/CD pipelines, versioning, audit trail, etc.
FWIW: It reminds me a lot of what Pat Nadolny has set up at Arch using Meltano.
Where does starlake.ai bridge that gap?
If you think about it from this perspective, lacking a good answer to the one question every startup should be able to answer, the question becomes: for whom is starlake great at bridging this gap?
There are already lots of ways to bridge the gap, rolling out analytics engineering inside companies, forming cross-functional teams, or deploying a data mesh. Starlake shines where the gap matters, but those changes won’t do it.
Those are spaces where machine learning and AI aren’t the sole focus, where data is important but likely mainly used in smaller data science projects and analytics. It’s a place that isn’t entirely data-driven. It’s kind of a space “in-between.”
Interestingly, a bank's analytics department fits this description, as do probably a bunch of others.
So, what’s interesting about starlake.ai?
A few random thoughts on starlake
I’ve always admired consultants who turned their work into a profitable SaaS company. Fishtown Analytics did it (now DbtLabs), but many don’t and won’t because it’s hard. I like the approach because it means you’re likely already profitable and know your niche well. But it also means you might be focusing on the wrong things and might lack the product skills to pull it off. Consultant work is very custom, while building a SaaS company means finding commonalities and making a great product out of them, which is the opposite of custom work in a sense.
But Starlake already brings a bunch of interesting features, one of which is that they claim the pricing is “for free.” I’d say they provide an open-source solution and haven’t yet decided on how to work with open-source as a business strategy (I have a ton of thoughts on that one…).
Starlake automatically generates DAGs, which sounds like an impressive feature. After all, orchestrating and optimizing DAGs is one of the core tasks and core pains of data engineers. So, in theory, this is an amazing feature; the question, of course, is how good it is in the jungle most data engineers find themselves in.
The tool also provides a different perspective on data freshness. It doesn’t let you define a schedule for workload runs, instead you’re asked to provide how fresh you want your data to be. That’s a pretty unique perspective, and again, it’s a glimpse of what it means to “remove data engineering,” but yet again, I’m unsure of how well it works.
It’s all I got for now, if this sounds super interesting to you, check out the tool and find out for yourself whether it makes sense for you (and tell me about it!).
Thank you, Sven, for sharing your thoughts on Starlake. I work in the agriculture sector, and we use Starlake daily to extract and ingest data, generating DAGs from templates to orchestrate everything. For now, our ingestion DAGs are scheduled rather than event-triggered. We are considering using transformations and taking advantage of column-level lineage to identify the origin of downstream data.
Thanks Sven for this thoughtful article! Addressing your point about what makes Starlake a game-changer: one of our banking clients reduced their data pipeline development time by up to 90% using Starlake. They're thrilled because it automates complex data engineering tasks, improves data quality, and accelerates insights. This transformation has been a 10x improvement over their previous setup. We're excited to continue helping companies bridge the data engineering gap and achieve outstanding results!