
Sam Altman Is Right: Wrappers Will Die. He Just Forgot He Built One.
The three-layer architecture that survives every model drop — and why OpenAI can't build it.

In 2006, Amazon wasn’t a cloud company. They were a retailer with a massive infrastructure problem — and Jeff Bezos saw something that would become a trillion-dollar insight.
Every team at Amazon was building their own infrastructure. Their own servers. Their own storage. Their own compute. It was expensive, slow, and stupid. So Bezos mandated a different approach: standardize the interfaces, make everything swappable, let teams pick the best tool for each job.
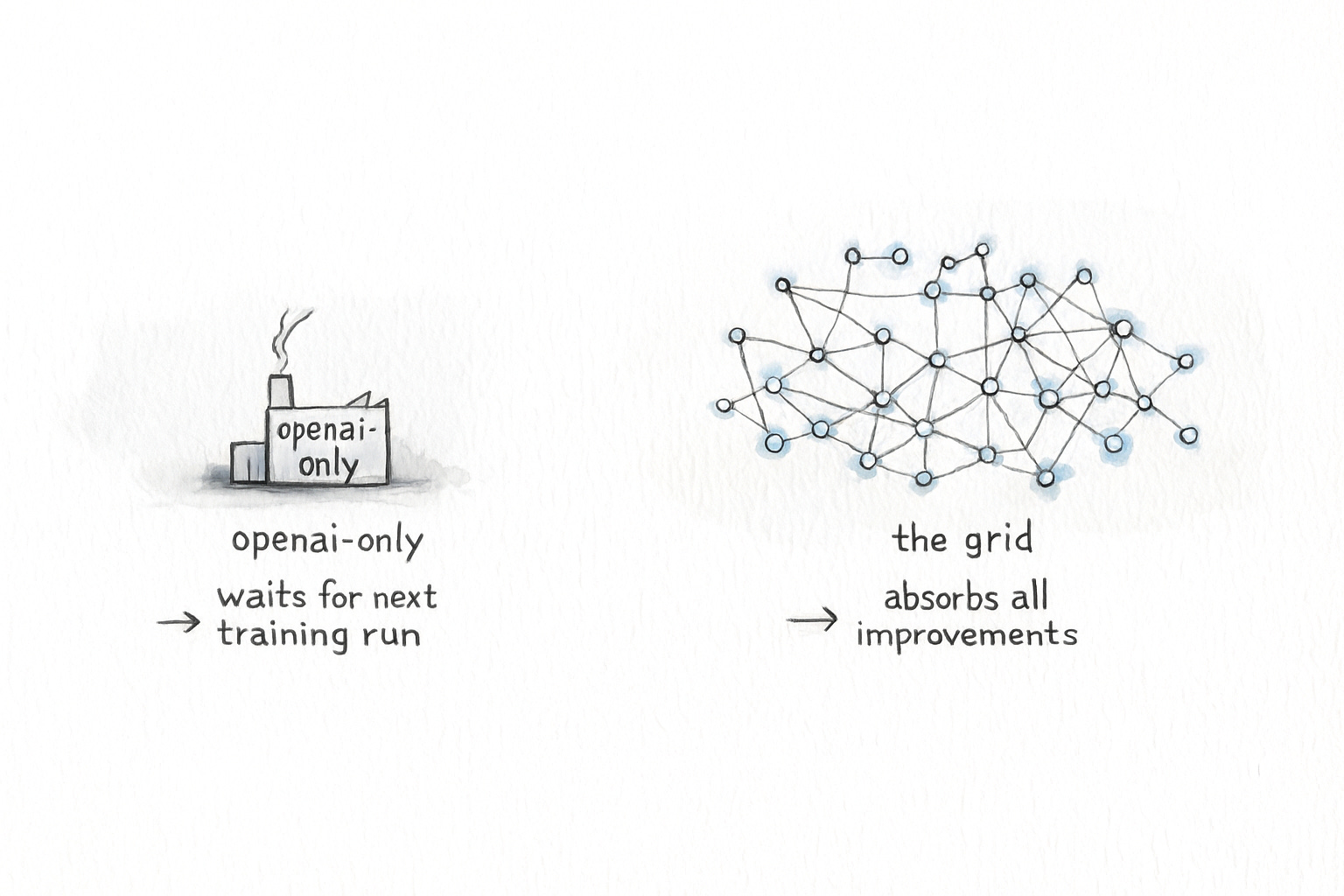
Don’t build a power plant. Build a grid.
AWS became the grid. Any compute, any storage, any database — plug it in, swap it out, upgrade without rebuilding. When better services launched, every AWS customer got access instantly. The grid compounds because it absorbs every improvement from everywhere.
OpenAI is the anti-AWS, for themselves at least.
Two hundred million users, and they’re locked into a power plant. When Claude improves, ChatGPT users can’t access it. When DeepSeek proves you can match frontier performance at a fraction of the cost, ChatGPT users can’t access it. OpenAI is trapped by OpenAI.
Sam Altman warned founders in 2024: “If you’re just wrapping GPT-4, we’re going to steamroll you.” He was right. But he missed the bigger picture: OpenAI is wrapping GPT too. They just wrapped their own model.
Vertical integration feels like a moat until the market moves faster than you can. Then it’s a prison.
The AI products that survive won’t have the best features. They’ll have model-agnostic architecture — the same architecture that made AWS dominant. Here’s three principles that will work. Bezos proved them. Apply them or get steamrolled.
If you only have 5 minutes: here are the key points
OpenAI has a “wrapper problem” too: Despite Sam Altman’s warning to founders not to just wrap GPT-4, OpenAI itself has wrapped its own model — locking users into one model, one set of guardrails, one pricing structure.
AWS vs. OpenAI: AWS won by building a model-agnostic infrastructure — the “grid” — letting users swap in better tools instantly. OpenAI, by contrast, is a vertically integrated “power plant” that can’t absorb external breakthroughs.
The grid compounds AI progress: Model-agnostic products capture 100% of frontier improvements from all labs, while locked-in stacks get only a fraction. The gap compounds fast.
Three-layer architecture that survives every model drop:
Socket Layer – Standardize interfaces so switching models is a config change, not a rewrite.
Routing Layer – Automatically select the best model per task; users shouldn’t have to choose.
Replaceability Layer – Make every component (models, vector stores, safety layers) swappable to prevent vendor lock-in.
Moral of the story: Don’t build your stack around any single model provider. Build (or plug into) the grid — it’s the only structure that scales with AI’s pace.
OpenAI trapped 200 million users inside their own moat
The screenshot test feels brutal: take your product’s input/output, paste it into the newest foundation model, see how close the raw model gets to your value. Is it even better?
Example: Granola is an amazing meeting notes app, but transcripts are pretty easy to get nowadays. Go try it out, take a look at your granola notes from a meeting, copy the transcript + a screenshot of the video meeting and paste all of it into ChatGPT (of course in a privacy preserving way!) and tell ChatGPT to write “Granola style” meeting notes. ⇒ That’s what a potential wrapper problem looks like (which is sad because I do think the CEO of Granola is a top strategic thinker on exactly this topic!)
Thank you, ChatGPT, now that’s a reason to feel absolutely destroyed today…
If the answer is “uncomfortably close,” you have a wrapper problem. But OpenAI has a wrapper problem too. They wrapped their own model (very thinly!) and called it a product.
Think about what happens when Claude 4 drops with better reasoning. Or when Gemini ships superior code generation. Or when the next open-source model matches GPT-4 at 1/10th the cost.
AWS customers get access to whatever’s best. That’s the whole point — the grid doesn’t care who produces the electricity. It just delivers the best available power to whoever needs it.
OpenAI customers get GPT. Period. OpenAI’s improvements only. OpenAI’s guardrails only. OpenAI’s pricing only.
This is vertical integration’s trap. It feels like control — we own the whole stack! — until the stack starts losing to competitors you can’t absorb.
The datacenter companies learned this in the 2000s. They built their own infrastructure, which felt powerful until AWS customers could tap into whatever was best at any moment. When better hardware appeared, AWS customers got it. Datacenter owners waited years for their next refresh cycle.
Same dynamic, different decade. When better models appear, model-agnostic products get them. OpenAI waits for their next training run.
Model-agnostic gets 100% of all AI progress — locked-in gets 20%
Here’s the math that should terrify every vertically integrated AI company.
If you’re locked into one model provider, you get 100% of their improvements and 0% of everyone else’s. Five major frontier labs now. You’re capturing maybe 20% of total AI progress.
If you’re model-agnostic — if you’re a grid — you get 100% of all improvements. Every lab’s breakthroughs become your breakthroughs. The gap compounds with every release cycle.
AWS understood this from day one. When Lambda launched, every AWS customer could use serverless compute immediately. When Aurora launched, every customer got access to a better database. AWS didn’t build all these services to be generous — they built them because the grid that offers the most options wins.
Now apply that to AI.
When Anthropic improves Claude’s reasoning, model-agnostic products route reasoning-heavy queries to Claude. Their users get better answers. OpenAI users get nothing.
When DeepSeek proves frontier performance is possible at 1/10th the cost, model-agnostic products cut their API spend overnight. OpenAI users keep paying full price.
When the next breakthrough happens — wherever it happens — grids absorb it instantly. Power plants wait and hope their internal R&D catches up.
The compounding gap only widens. More labs reaching frontier capability. Release cycles accelerating. The tax for being locked into a single provider gets more expensive every quarter.
You can’t out-feature this gap. You have to out-architecture it.
1. The Socket Layer: Standardize interfaces so model switches become config changes
AWS won because every service speaks the same language.
S3’s API is S3’s API. The underlying storage infrastructure has changed a dozen times since 2006. Customers don’t care. They never rewrote a line of code. The interface stayed stable while the implementation improved.
This is the socket layer principle: standardize the interface, not the implementation.
Your AI stack needs the same. A unified abstraction that every model plugs into. No GPT-specific prompt formats in your business logic. No Claude-specific schemas in your codebase. No Gemini-specific function calling syntax anywhere near your application layer.
Everything goes through the socket.
Thing is, sockets are actually hard to build. OpenAI have already built very different APIs. Even the functionality of the models are very different. Meaning you’ll have to put in extra work to make it work (but that’s why it will turn into a moat!).
When a new model drops, you add a translator to your socket layer. Your business logic never changes. Your prompts don’t get rewritten. Your application doesn’t know or care which model is generating the response.
AWS didn’t ask you to rewrite your application when they upgraded their hardware. Your AI stack shouldn’t ask you to rewrite prompts when you switch models.
Without a socket layer, every model switch is a rewrite. With it, every model switch is a config change.
That’s the difference between the grid and the power plant.
2. The Routing Layer: Stop making users pick models — they’ll pick wrong 85% of the time
AWS doesn’t force you to use one database.
Need key-value storage? DynamoDB. Need relational queries? RDS. Need high-performance analytics? Redshift. The platform offers options. You pick the best tool for each job.
More importantly: you don’t have to become an infrastructure expert. AWS provides enough guidance that a developer can make reasonable choices without understanding the internals of every service.
Your AI stack needs the same principle: automatic selection of the best model for each query.
I learned this the hard way at MAIA.
When we launched, we gave users a choice between GPT-4, Claude, and Gemini. Felt like good UX — give people control. Then I looked at the data: only 15% of users picked the best-performing model for their specific queries. The other 85% stuck with whatever default they’d set months ago, even when a different model would handle their question dramatically better.
We removed the choice. Made the system pick automatically.
Success rate jumped from 15% to 95%. Three persistent customer complaints vanished overnight — not because we retrained anything, but because we stopped making mechanical engineers become AI model experts.
The override rate now? Under 5%. And falling.
That’s not users losing control. That’s users trusting the system because it makes better decisions than they would.
AWS figured this out years ago. They don’t expect every developer to understand the tradeoffs between io1 and gp3 EBS volumes. They provide sensible defaults and let the platform optimize. The best infrastructure disappears. You just get results.
Your AI routing layer should do the same. Users don’t want to choose models. They want correct answers.
3. The Replaceability Layer: If your vendor died tomorrow, recovery should take hours not months
AWS services come and go. You can swap.
SimpleDB gave way to DynamoDB. Classic load balancers gave way to application load balancers. Old instance types get deprecated, new ones launch. The ecosystem evolves constantly.
But AWS customers don’t rebuild their applications every time. They migrate. They swap. They upgrade. Because AWS designed for replaceability from day one — no single service becomes an architectural dependency that can’t be changed.
Your AI stack needs the same principle: every component hot-swappable.
Not just the language model. Everything.
Embeddings. If you’ve hardcoded OpenAI’s embedding model into your retrieval system, you can’t switch when a better embedding model drops. Abstract the interface. When Cohere or Voyage releases something better, you should be able to switch in an afternoon.
Vector stores. Pinecone today, Qdrant tomorrow. Your application logic shouldn’t know which one it’s talking to.
Safety layers. If you’ve baked OpenAI’s content filtering into your pipeline, you’re locked into their moderation decisions. Abstract it. Make it swappable.
The test is simple: if [vendor] disappeared tomorrow, how long would it take you to recover?
If the answer is “months,” you have architectural dependencies that will eventually become liabilities. Every dependency you can’t swap is a bet that this vendor will always be the best option. That bet gets worse every quarter as the market evolves.
AWS never bets on a single vendor — including themselves. They offer multiple options for almost every category. They know lock-in is a trap, even when it’s their own lock-in.
Build your AI stack the same way. Every component replaceable. Every vendor swappable. Every model expendable.
The grid wins, so bet on the grid.
Bezos figured this out in 2006.
Don’t build a power plant. Build a grid - or plug into it. The grid absorbs every improvement from everywhere. The grid compounds. The grid survives.
OpenAI built the world’s most impressive power plant — and locked two hundred million users inside it. When the next breakthrough comes from Anthropic or Google or DeepSeek or a lab that doesn’t exist yet, those users are stuck. They’ll watch the grid customers absorb the improvement instantly while they wait for OpenAI to catch up.
Your product will face the same test.
Every model drop, the screenshot test gets harder. Every release cycle, the gap between “your carefully designed product” and “paste this into the new model” gets smaller. You can’t out-feature that gap. It compounds too fast.
But you can out-architecture it.
Socket layer: standardize the interface, swap models freely. Routing layer: let the system choose the best model for each job. Replaceability layer: every component hot-swappable, every vendor expendable.
That’s the grid. That’s what Bezos built. That’s what made AWS a trillion-dollar business.
OpenAI is the anti-AWS. Vertical integration. One model. Their stack or nothing.
Tap into the grid instead.
Vertical business build by innovation; the ‘grid’ so called innovation was from a shopkeeper trying to cut costs, the vertical resulted in Mercedes Benz, iPod and started how I am reading your article full of fallacies.