
Good AI, great AI
What the fastest AI companies do differently (and why it looks wrong).

Cohere should have been one of the defining companies of the LLM era.
Founded in 2019 by Aidan Gomez, one of the co-authors of Attention Is All You Need, Cohere had the experts, the timing, the enterprise focus, and the transformer lineage itself. Anthropic came later, in 2021, founded by former OpenAI people with a safety obsession that sounded, at the time, like it should slow them down.
By 2026, the gap was absurd. Cohere was in the low hundreds of millions of ARR. Anthropic had raised at a $380B post-money valuation and was reported at tens of billions in annualized revenue.
This piece is about why.
Not because Cohere is bad. Cohere is an extraordinary company. That’s the point. The interesting comparison is not great versus stupid. It is GREAT versus merely GOOD. In this market, merely GOOD is still a fast scaler. The Coheres, the Harveys, the Mistrals. None of them are Anthropic.
I wanted to understand the difference properly. So I treated the question like a research project.
Tackling the “how to build great AI products” question as a real research project
This is not a newsletter article about AI. Not really.
I could’ve generated one of those in fifteen minutes. So could you. So could anyone with a Claude tab open and a vague opinion. Which is roughly why I’ve stopped reading most newsletters this year. Too much opinion, not enough research.
So I did the opposite.
I write this newsletter every single week, two hundred straight weeks of it. I took the time I usually spend on eight editions and dumped it all into one question. 100+ hours. Hundreds of thousands of words of research. Four books, none of which I’d recommend to anyone I like.
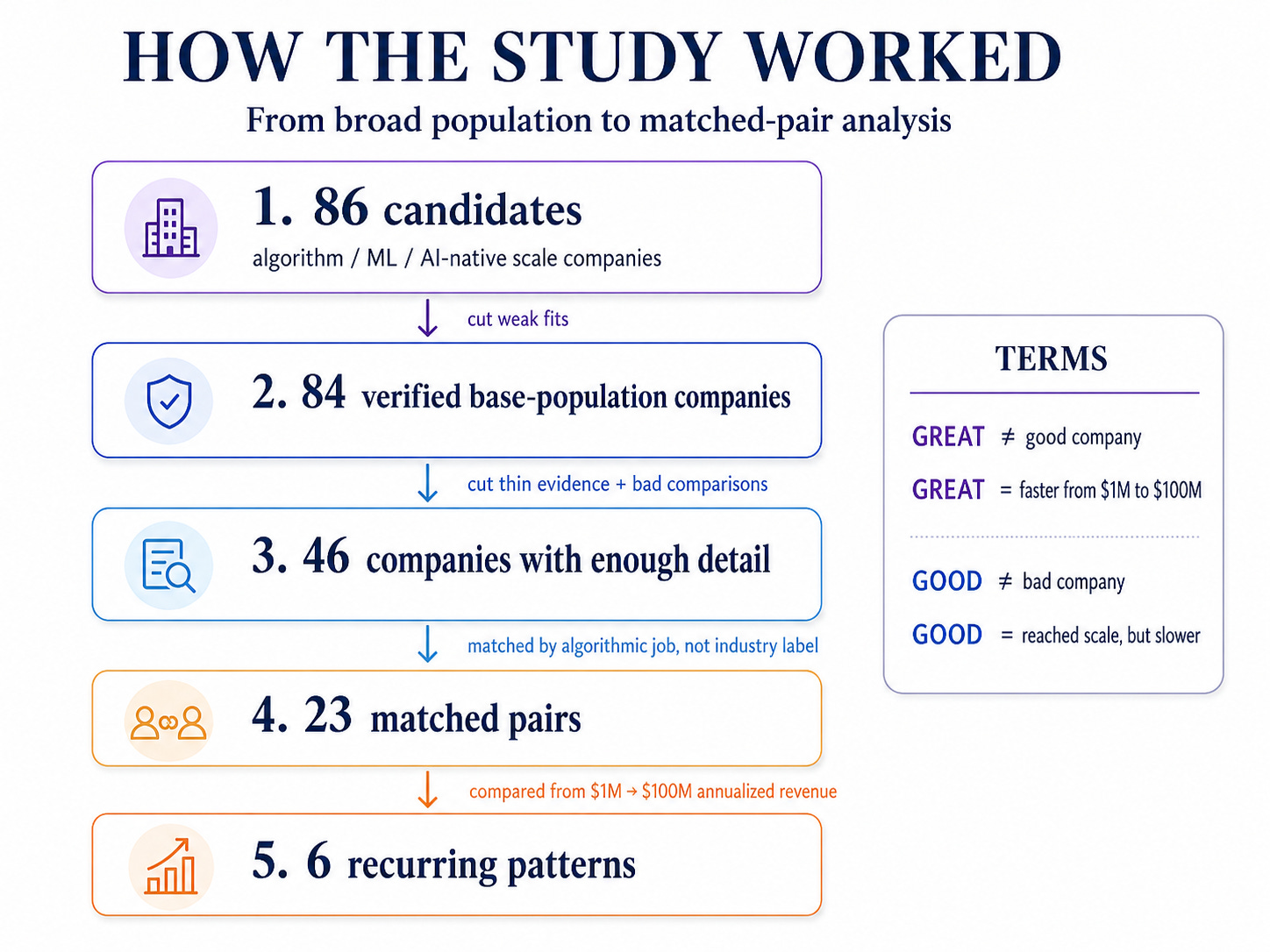
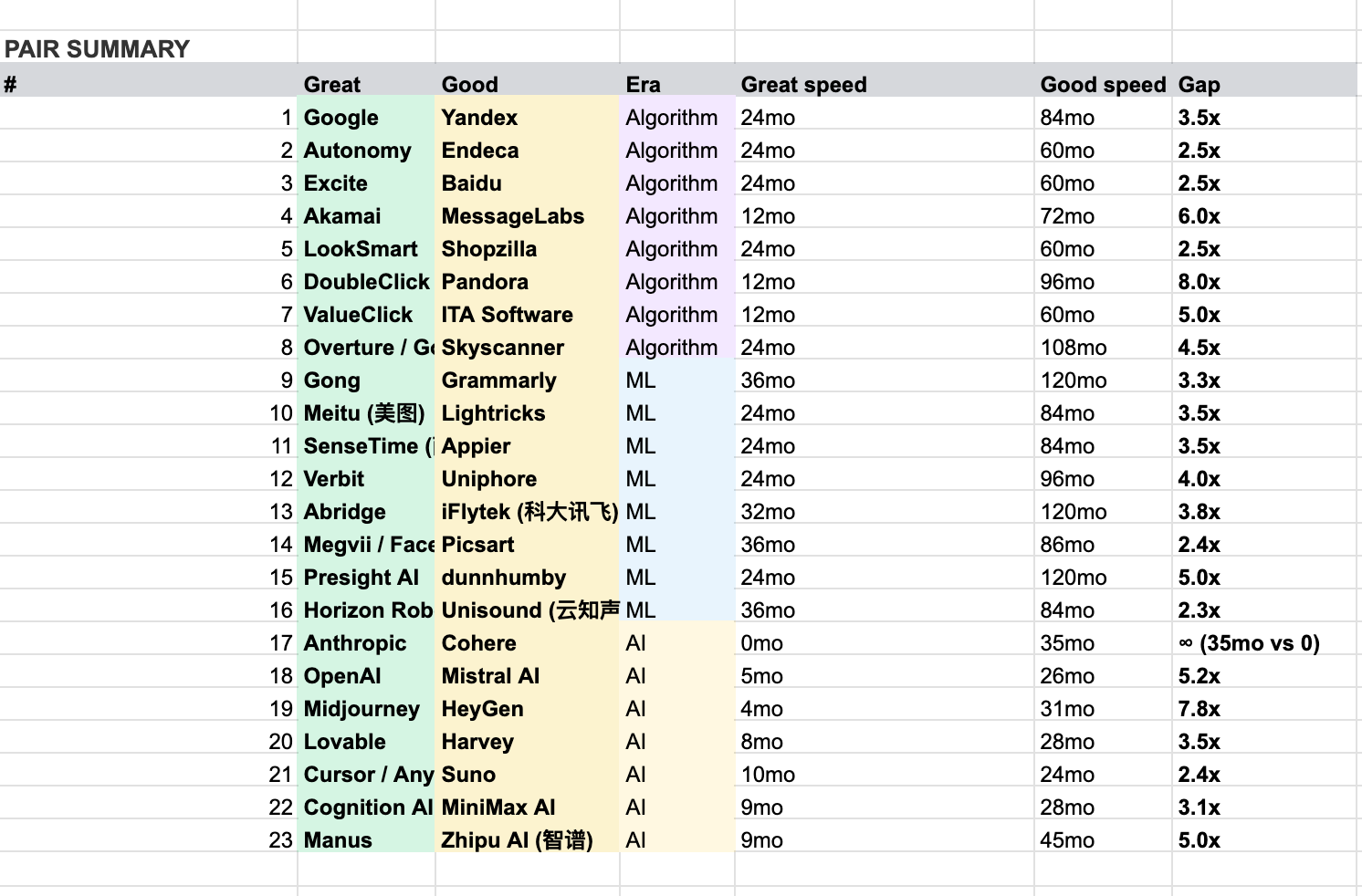
And an actual research methodology loosely cribbed from Jim Collins’s Built to Last: 23 pairs of companies in roughly comparable starting positions, drawn from a population of 86 algorithm/ML/AI scalers I could verify across thirty years. Two companies per pair, one GREAT and one merely GOOD. The methodology section explains how it actually worked.
One example of the kind of thing that comes out of digging into actual companies instead of writing AI takes:
DoubleClick was, in my view, the closest thing the pre-2000 internet had to a proto-AI company. The architecture that defined web monetization for the next thirty years. Where did the idea come from? Two guys in a room asking “what do people do to make money?” Someone said “banners on websites, I guess.” That’s the origin. A banal brainstorm. You will not find that story in any AI book published this year. There are about a hundred details like it in the 15 thousand words ahead.
My research question: what separates GREAT AI products from merely GOOD ones?
The pattern was easier to name than I expected, and much harder to live with.
The GREATs kept making decisions that looked locally absurd: too narrow, too messy, too expensive, too slow to monetize, too hard to explain in a board deck. The GOODs chose the cleaner explanation almost every time.
The GREATs had a stomach for locally absurd decisions. The GOODs didn’t.
But “locally absurd” is not a personality trait. It is what a good decision looks like when the room is optimizing for the wrong layer.
The move looked wrong at the product layer and right at the data layer. Wrong at the current revenue layer and right at the future loop layer. Wrong inside the regime and right after the regime changed.
The six weird looking moves
1. Make the product uglier so it can label itself.
A clean product asks for feedback later. A labeling machine turns the next click, edit, accept, reject, upscale, or signature into training data.
2. Stop polishing the thing that is already good.
GREATs rotate at 8/10. GOODs keep improving the node current revenue still rewards, because it feels rational right until it slows them down.
3. Leave the product surface and follow the buyer’s money.
The locally sane move is to make writing better, search better, transcription better. The compounding move is to ask where the buyer’s economic value moves next.
4. Fund bets that look stupid as products but rational as signal.
Loss-making phones, negative gross margins, delayed launches, weird wrappers. The product math says no. The signal math says maybe.
5. Overbuild the boring data machine before anyone believes it matters.
“Data-centric AI”: Rubrics, expert labelers, failure lists, weekly cadence. It looks like operational overkill until the competitor with “cleaner SaaS” cannot learn fast enough.
6. Remove the “kitchen”, even when the kitchen is where today’s revenue lives.
Redirects, sales processes, no-training clauses, partner surfaces, privacy boundaries. They all look commercially reasonable. They all put distance between the model and the money.
The Anthropics of this study weren’t smarter, better-funded, or first. Half the time they were last. The Coheres were thoughtful, articulate, and right about everything inside the regime they were operating in. That was the problem.
The Anthropics simply grow much faster, from PMF (measured as $1M ARR) to my scale threshold status (measured as $100M ARR).
One last warning, because the rest of the piece earns it: most of what I expected to find on the way to that answer was wrong. Here’s a preview of 6 beliefs I held that the research busted wide open:
Six things I no longer believe
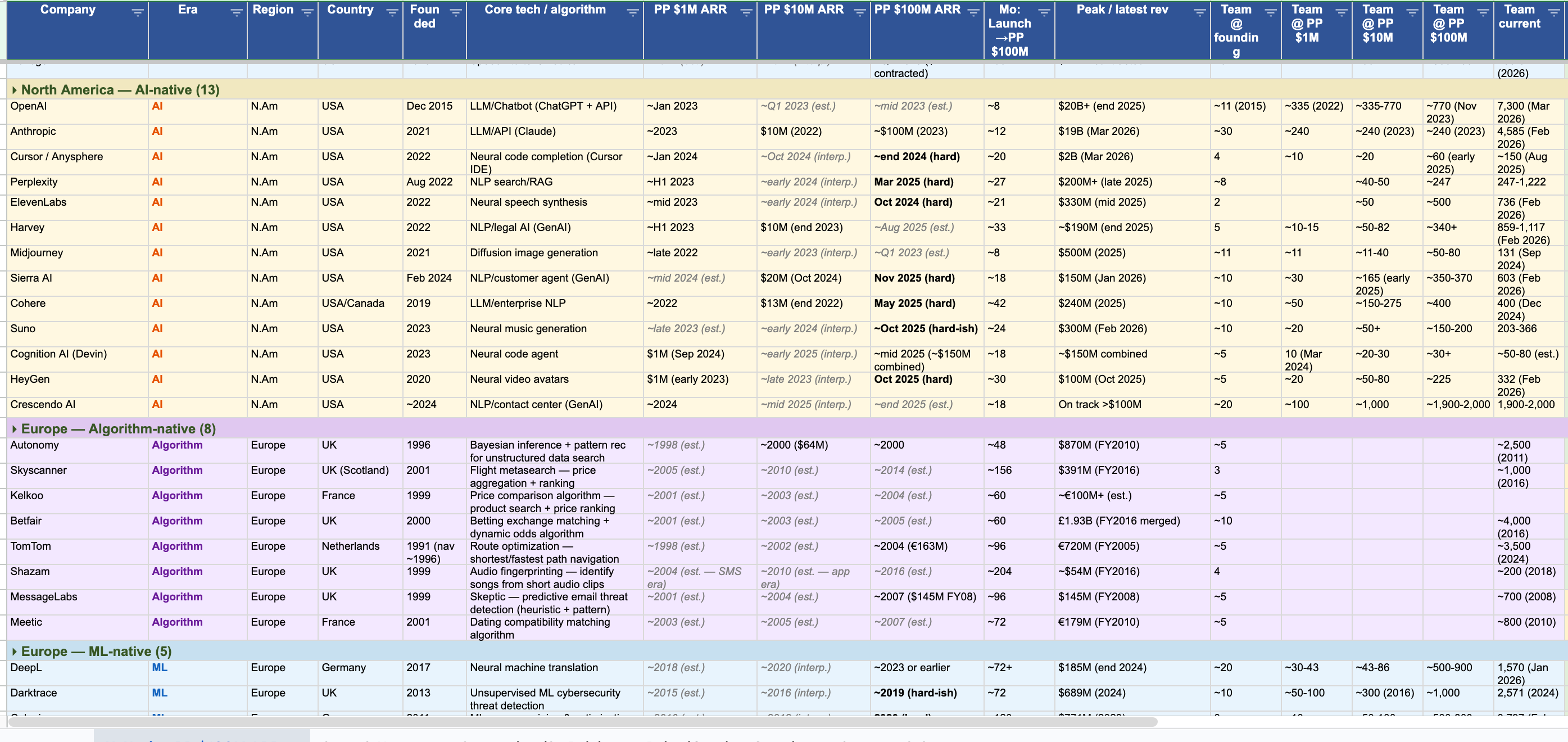
1. AI-native speed comes from the LLM APIs. Wrap and ship. Reality: Both sides of every matched pair have access to the same APIs. Some train their own models, some wrap, and the wrap-or-train decision turns out to be uncorrelated with greatness. APIs explain why this era is fast. They do not explain why some companies in this era are four times faster than the others.
2. OpenAI will take it all. Reality: Take-it-all stories have been told about every dominant company in every era of this research, and they have been wrong every single time. Search didn’t collapse to one winner. Recommendation didn’t. Computer vision didn’t. Translation didn’t. Markets that look like winner-take-all from inside the wave reliably resolve into winner-take-most, with the runners-up still hitting scale threshold.
3. AI in 2024 is a brand-new game. The old patterns don’t apply. Reality: The pattern has been running for nearly thirty years across three foundational eras. Each era produced its own GREAT and merely GOOD companies, and the variables separating them have been roughly the same for three decades. Today’s frontier-model GOOD is the same shape as yesterday’s morphological-search GOOD and the year-2000 ad-network GOOD. Names change. Patterns don’t. APIs are this era’s accelerant, not its secret.
4. Big proprietary data is a moat. Reality: Data alone is not a moat. One of the largest exclusive consumer datasets in retail history sat inside a company for thirty years and never compounded past consultancy scale. Most of the proprietary datasets in this study turn into no advantage. Data is the opposite of oil. With oil, the extraction is most of the work. With data, extraction is cheap. The refinement is the game.
5. Real focus means one bet at a time. Reality: The companies that compounded ran several uncomfortable bets simultaneously, most of them looking like distractions. The bets paid off in combinations that weren’t in any plan: surface A’s data made surface B’s product work, which made surface C viable. The slower companies ran one (signal) bet at a time and waited for evidence before authorizing the next. They got one answer per year. Their counterparts got three. Real focus is narrow interaction primitive, not narrow scope of action.
6. The companies that take longer are missing something obvious. Reality: They weren’t. They were thoughtful, articulate, and wrong. The merely-GOOD CEOs can and do explain on the record exactly why they aren’t doing what their faster-scaling competitors are doing. The explanations are correct in every internal sense. They are also disastrous. Thoughtful coherent decisions are not enough in a complex field. Messy probing is how you discover the thing no memo could justify yet. Which also explains why there is no playbook.
If best practices are wrong and there’s no playbook, what’s left to learn? Six concepts that held across the study, deep, researched, and accompanied by real stories from the people who made the decisions at the time. The point of doing this research was to figure out what I can do to make sure our company goes from PMF to scale status as fast as possible. The six concepts are an answer.
Now let’s talk about the population of the study and what struck me as interesting right away.
Bad Boys Move in Silence
David Senra at Founders likes to say bad boys move in silence, he is right.
Not morally bad. The companies that matter often don’t announce themselves as the ones that matter.
Ask an AI founder which companies they study and you get the same list: OpenAI, Anthropic, DeepMind, Cursor, Midjourney, maybe NVIDIA, maybe Google if they are feeling historical. It is not a bad list. It is just a loud one. Loud companies are not the population. They are the press cycle.
So I tried to build the full list, removing the “loud bias” at first.
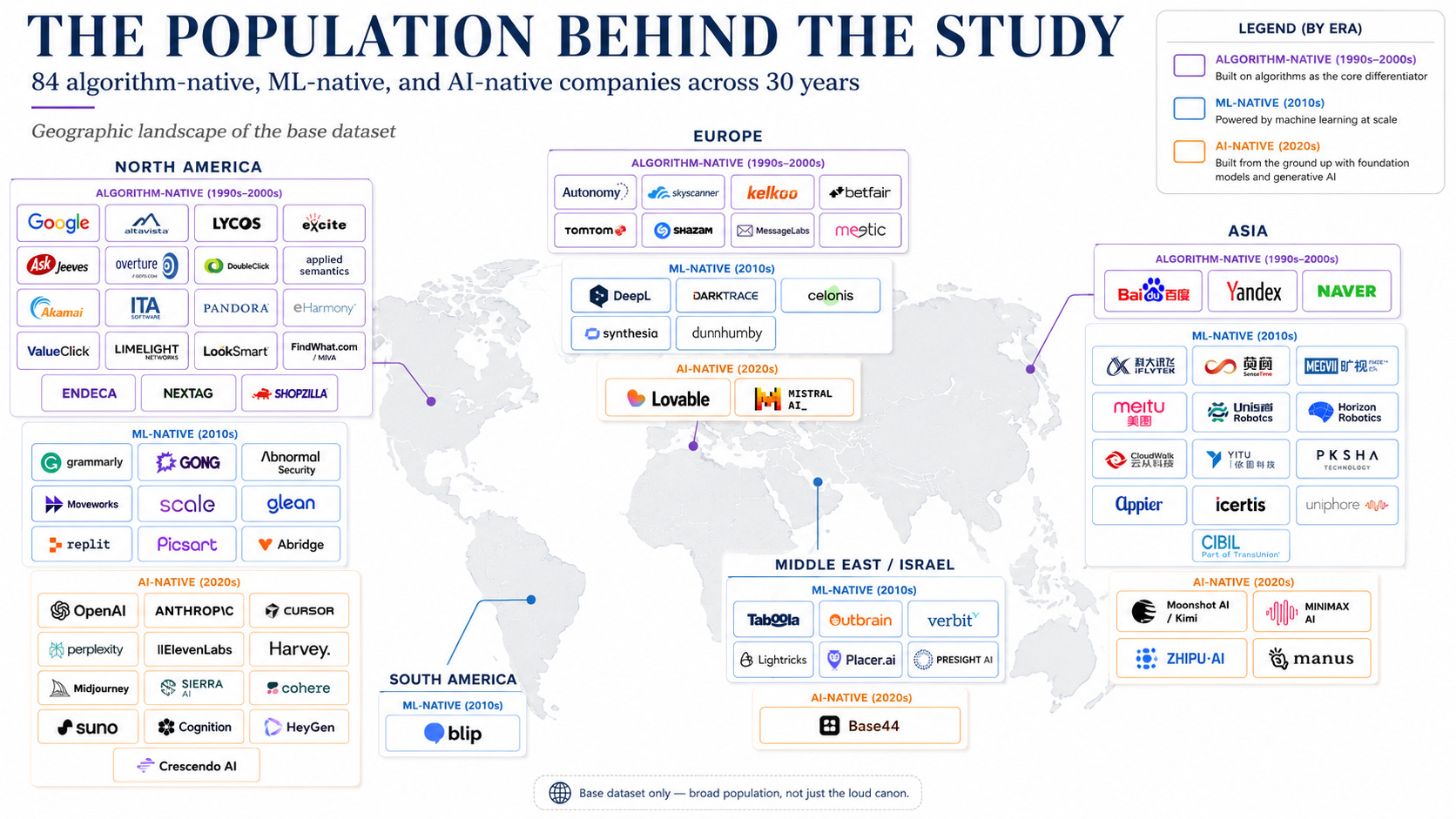
The task was simple enough: find every company I could verify, anywhere on earth, across the last thirty years, that reached the scale threshold outcomes with an algorithm-heavy, ML-heavy, or AI-native product at the core.
Not “used AI.” Not “had a recommendation feature.” Not “mentioned machine learning in the S-1 because the market was paying for it.” My test was whether the company’s core product would become meaningfully worse, or cease to exist, if the algorithmic system were removed.
I expected more than what I found: 86 candidates I could defend as “core algorithmic/ML/AI product”. On the entire planet. Across three eras: algorithm-native, ML-native, AI-native.
That number did two things to me.
First, the field felt smaller. For all the noise, the actual population of algorithmic companies that reached this scale is not that big.
Second, once you leave the loud canon, the field gets weird fast.
DoubleClick should be required reading for every AI founder and isn’t. Overture got hissed at on stage before inventing the paid-search architecture that ate the internet. Meitu reached public markets with selfie apps, loss-making phones, and later a crypto gain larger than full-year operating profit. dunnhumby knew more about Tesco’s customers after three months than Tesco knew after thirty years and still became a consultancy. LookSmart was running data-centric AI in 1999 with two hundred professional ontologists before anyone outside the room had a name for the discipline.
And behind those sat an entire Chinese computer-vision-and-speech wave (iFlytek, SenseTime, Megvii, CloudWalk, Yitu, Unisound, Horizon Robotics) that Western AI discourse mostly treats as background noise (”they don’t matter because they are from China and subsidized” - not true in terms of this research, not what the data and the stories say).
This is why the article does not start with OpenAI.
OpenAI is loud. Anthropic is loud. Cursor is loud now. Useful, yes. But loudness is not evidence.
How I Tried Not to Mistake the Press Cycle for the Population
I used six rules.
1. Build the base population first. I looked for every company I could verify that reached the scale threshold outcomes with an algorithm-heavy, ML-heavy, or AI-native product at the core. That produced 86 candidates. Not all of them made it into the final study. Some were too opaque, some could not be paired cleanly, and some had too little revenue data to compare honestly.
2. Use $100M revenue / ARR as the scaling threshold, not valuation. Valuations are noisy, especially across eras. Revenue is also imperfect, but less stupid to compare. $100M is arbitrary in the way all thresholds are arbitrary, but it is high enough to rule out demos and low enough to compare across eras. For older companies, I inflation-adjusted so that a 1999 company is not being judged against a 2025 dollar. The threshold is operational, not financial. It is the moment a company crossed into “this is real revenue, not narrative.”
3. Use matched pairs, not vibes. I stole the Jim Collins move: start with a population, separate GREAT from GOOD by a wide performance gap, then match companies that began from roughly comparable starting conditions. Matched pairs cancel out some of the weather. If both companies ride the same hype cycle, the hype matters less. What remains is more likely to be the variable you care about.
4. Study three eras, not just the current AI wave.
The AI-native era is too young and too polluted by hype to study alone. ChatGPT is not the beginning of the story. It is the moment the story became obvious to everyone.
The pattern came in three waves: algorithm-native companies from roughly 1995–2005, ML-native companies from roughly 2005–2021, and AI-native companies from 2021 onward. The names changed: ad matching, search ranking, speech recognition, computer vision, recommendation, generative language. The operating problem did not. Each wave had companies trying to turn data into better predictions, predictions into better products, and products into more data.
That is why the old cases matter. DoubleClick is not historical decoration. Yandex is not nostalgia. dunnhumby is not a retail tangent. They are earlier runs of the same machine under different constraints.
Hypotheses that only explain ChatGPT-era companies are probably takes. Hypotheses that survive all three eras are worth taking seriously.
5. Build hypotheses backward. Test them forward. The old companies generated the hypotheses. The new companies tested them. This matters because otherwise you fall in love with whatever Cursor or Anthropic did last week and call it a law of physics. The AI-native companies were the test set, not the training set. Last-to-first kills the “this is the new thing” bias.
6. Throw away companies I could not compare honestly. The base population started at 86 candidates. 84 of them had enough confirmed data for the population-level analysis. 46 had enough detail and a credible matched pair to make it into the final 23-pair study. That means I cut a lot. Not because they were uninteresting, but because interesting is not enough, I need data.
Then I wrote the thing you are reading.
The Matched-Pair Sample
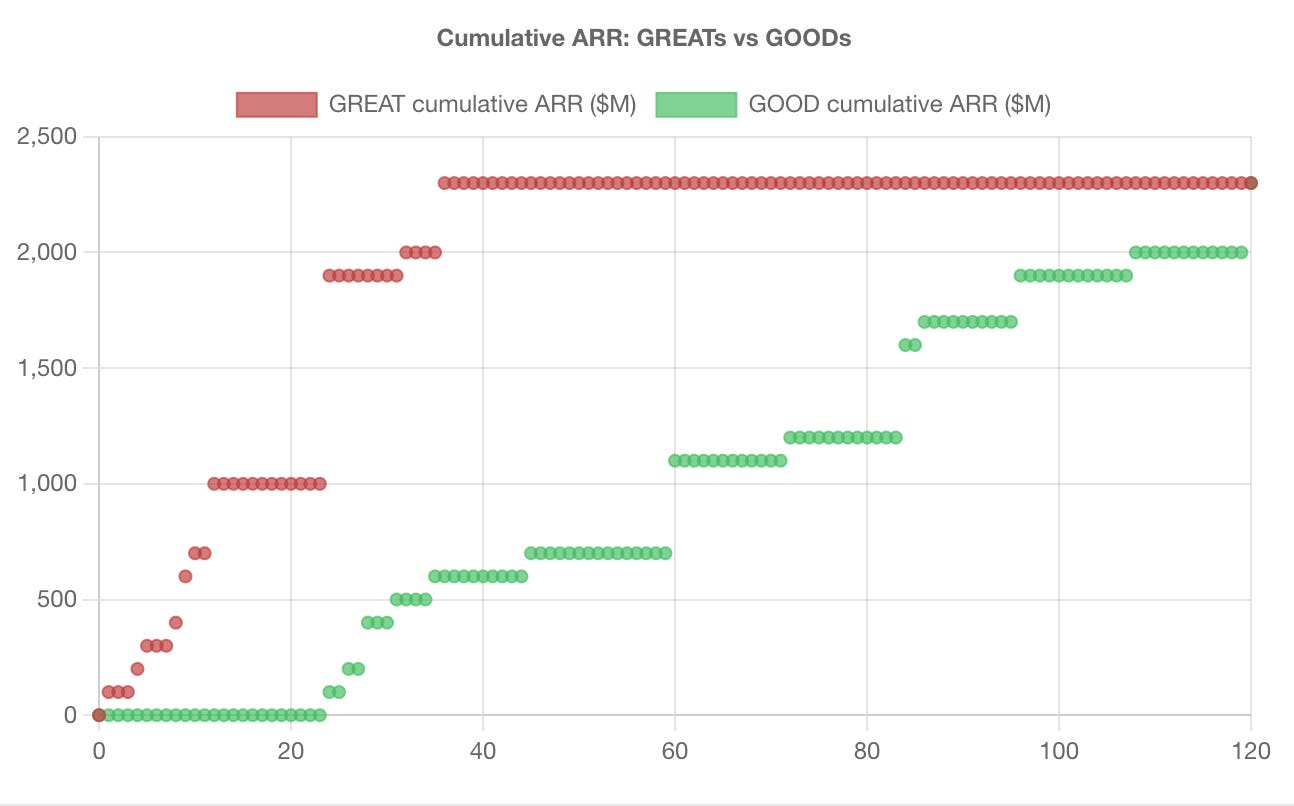
Each pair contains one GREAT and one GOOD company.
GREAT does not mean morally great. It means fast. The GREAT in each pair reached $100M in annual revenue / ARR significantly faster than its matched GOOD, starting at 1M ARR. This is important, as founding and reaching 1M ARR is a very different game than going from that 1M to 100M.
The matching is not based on industry labels. Industry labels are often the trap. DoubleClick and Pandora do not look like competitors. One sold ad infrastructure, the other sold internet radio. But both were algorithmic matching businesses founded before the dot-com crash, both matched inventory to users in real time, both depended on feedback loops, both reached scale. The relevant similarity was the algorithmic substrate. The relevant difference was the architecture of the loop. Pairing on industry would have missed that.
Same logic with Google and Yandex: same problem (search), same era, different regulatory and market geography. If a pattern shows up in both, it isn’t a U.S. tech-culture artifact.
Same with Meitu and Lightricks: same product surface (face manipulation, mobile), different countries (China, Israel), different financial regimes. If a pattern shows up in both, it isn’t local.
The goal was to cancel obvious external variables and leave the internal operating differences exposed. Some pairs will feel odd at first. Good. If the pair is too obvious, it often teaches less.
Across the final 23 pairs, the GREATs reached $100M roughly twice as fast as the GOODs in every era.

First hint that the pairing was not complete nonsense: the gap stayed consistent across eras. The interesting thing is that the speed gap held up across thirty years and three completely different technology paradigms. Whatever separates them is not era-specific. It compounds.
What the Population Already Said
Five things were striking about the 84-company dataset before I had done a single pairwise comparison.
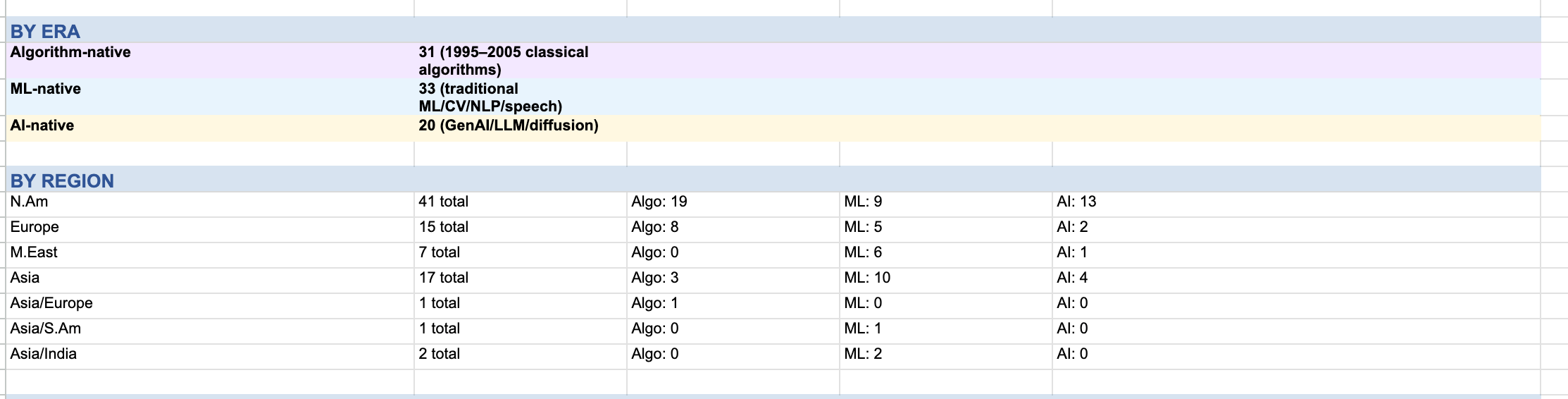
1. Asia is much bigger than the Western canon suggests. Across all 84 companies, Asia is 25% of the total. In the ML era specifically, fourteen of thirty-three companies are Asian — 42%. The computer-vision-and-speech wave was meaningfully run out of China and Korea, not Silicon Valley. The AI-native cohort is more US-heavy at the moment, but it is also young: the four Asian AI-natives in this dataset — Manus, Zhipu, MiniMax, Moonshot — all crossed $100M ARR in the last twelve months. If your AI history is mostly American, your pattern recognition is already biased.
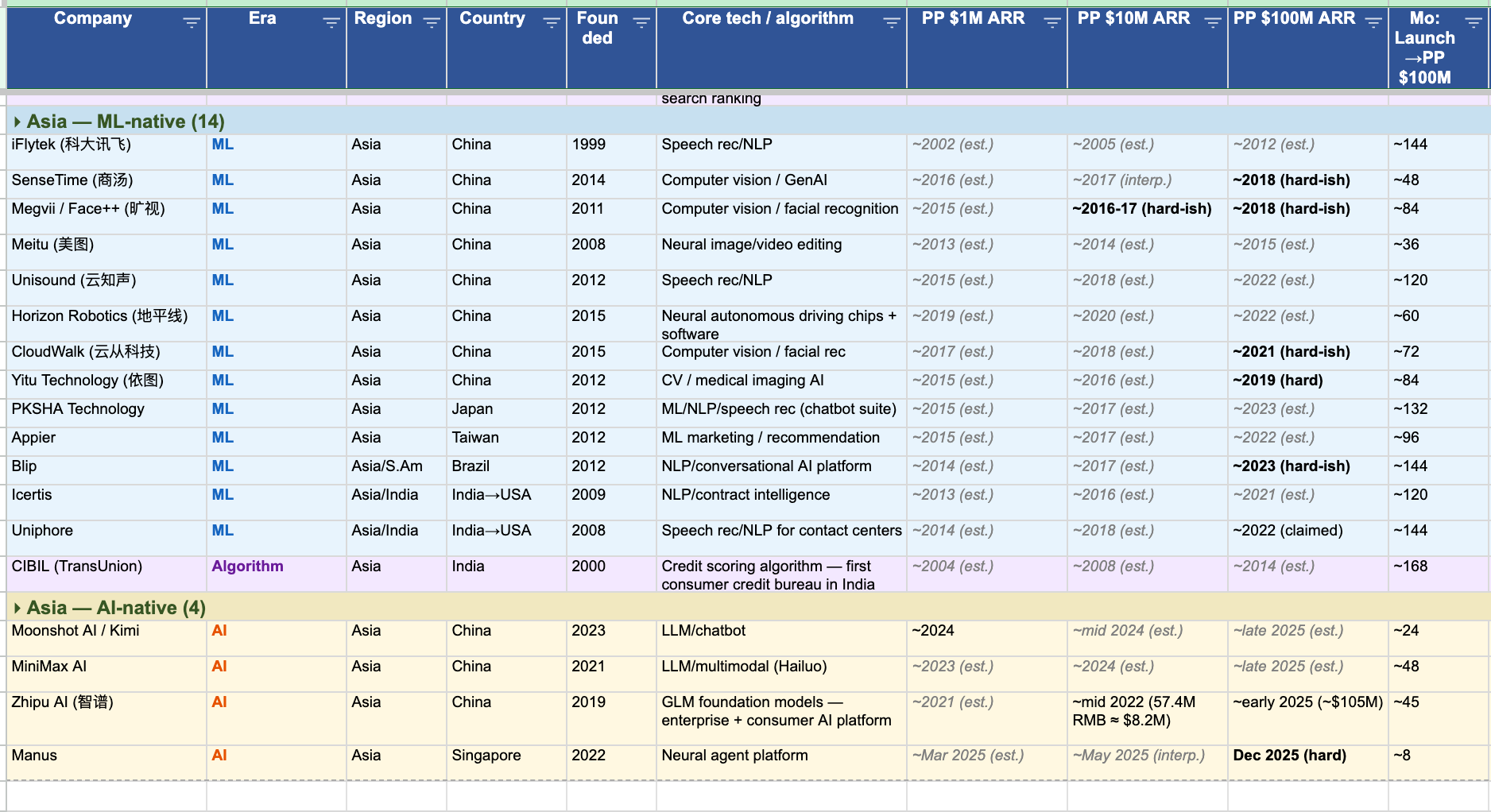
2. India is strangely absent. I expected India to show up alongside China. It does not. Indian-founded companies in this dataset are Uniphore, Icertis, and CIBIL, and the first two scaled from the US. There is no Indian GREAT in the strict sense across thirty years of data. The absence matters because India has the talent, the software export base, and the English-language advantage. The missing GREATs are not an obvious supply-side story. I don’t have a clean explanation. I think it’s worth one.
3. Africa is absent entirely. Zero companies. I tried. I didn’t find any. That does not mean no important algorithmic companies exist there. It means none cleared this threshold with enough verifiable data to enter the study.
4. Founder age doesn’t matter. I had assumed the AI-native era especially would be a young founder’s game. The data doesn’t bear it out. Neil Clark Warren founded eHarmony at sixty-six. Anton Osika founded Lovable in his early thirties. David Holz founded Midjourney in his late thirties after Leap Motion. The 84-company dataset has founders ranging from late-twenties through their sixties, with no correlation to the GREAT/GOOD verdict in any era.
5. The ML era was the slowest of the three. Median months from launch to $100M ARR: algorithm-native 66, ML-native 84, AI-native 20. The ML era is the slowest of the three. I do not have a clean causal story yet. But it matters because it breaks the obvious progress narrative. The ML era had better cloud, better tooling, more venture capital, and still scaled slower than the algorithm era on median.
How to Read the Rest of This Article
You’re not gonna be drowned in data, instead I’ve chosen to use stories (usually about pairs) to give you the ideas without too much of hard data processing on your end. So:
When a pair feels weird, don’t ask “Are these two companies competitors?” Ask “What variable is this pair trying to isolate?”
When a company sounds obscure, don’t ask “Why haven’t I heard of it?” Ask “What did it prove before the loud companies had a name for it?”
When a claim sounds too current, ask whether it also showed up in the algorithm and ML eras. If it didn’t, it’s hype.
No single case gets to carry the argument alone.
Caveats
Estimates. Almost none of these companies disclosed exact $1M / $10M / $100M dates. What they did disclose: revenue numbers in specific years, user counts at specific moments, funding events with implied revenue ranges, employee counts, IPO filings, founder retrospectives. Grammarly is the canonical fair-estimate case. Public breadcrumbs put them at roughly $1M ARR around 2011–2012 and roughly $100M ARR around mid-2022. Not perfect. Good enough to compare against Gong’s better-disclosed five-year path.
What this approach won’t catch. I missed companies. I ditched companies because I couldn’t argue clearly that the product is AI at core. Several Chinese companies are too financially opaque to verify. There are real GREATs out there not in the 84. Also, era assignments are based on each company’s original core technology, not what they run on now. Grammarly was founded in 2009 but compounded in the AI wave. Synthesia sits awkwardly between ML and AI. The assignments are defensible and good enough for the research method. They are not airtight.
Bias toward paper trails. The dataset is biased toward companies that leave paper trails. That is unavoidable. It is also why I treat absence (India, Africa, certain industries) as a finding to investigate, not a final truth.
Finally, here’s the full list of pairs studied:
Now let’s get started with the research hypotheses! I put them into six “Chapters” one for each major hypothesis I run a deep data analysis on (then refined the hypothesis and ran another analysis on).
Chapter 1: Build the labeling machine
Why every GREAT algorithmic product is a labeling machine in disguise.
“We shape our tools and thereafter our tools shape us.” — Marshall McLuhan
“Learning is not compulsory… neither is survival.” — W. Edwards Deming
In 2005, Tim Westergren explained Pandora’s strategy with a straight face: they were going to “really understand the sound of the music.”
They meant it. Thirty musicologists. Four hundred and fifty attributes per song. A multi-year effort to label the genes of music by hand. The Music Genome Project was a serious piece of work.
It was beautiful. It was also slow.
Pandora’s matched pair in this study is DoubleClick. Same broad era, same data hunger, same basic job: match one thing to one person. Pandora matched songs to listeners. DoubleClick matched ads to visitors.
Both believed in data. Both collected a lot of it. Both built matching systems before we called them AI.
The difference was that Pandora built a labeling project. DoubleClick built a labeling machine.
Pandora took roughly a decade to reach $100M in revenue. DoubleClick got there in a fraction of the time and sold to Google for $3.1B in 2007. The clue is in the name of a DoubleClick business unit from 1998: Closed-Loop Marketing Solutions. Nearly thirty years before everyone started saying “AI product,” DoubleClick had already named the thing that matters.
The product is the labeling machine.
I came in expecting the Bitter Lesson version of the answer: more data, more compute, more scale wins. That was wrong. GREATs and GOODs both love data. The difference is not how much they collect. It is whether the product turns the next user action into the next label.
My refined question: If both Pandora and DoubleClick spent a decade collecting and processing more behavioral data than nearly anyone else in their era, what’s the structural difference?
The finding is the Learning Tripod. A product learns fast only when three legs stand up together:
A narrow interaction primitive. One surface, one feedback unit, one repeatable user action per session.
A capture mechanism. Some invented or controlled technology that reads behavior at the right granularity.
An in-session loop. The user’s current action becomes signal for the next session’s product behavior.
Remove one leg and learning does not slow slightly. It falls over.
GOODs usually have one or two legs and often polish them beautifully. The missing leg is what kills compounding. In the study, 18 of 23 GREATs run all three legs actively. Only 3 of 23 GOODs do. The pattern replicates across industries and eras. The gap between Pandora and DoubleClick looks a lot like the gap between Harvey and Abridge (an AI era pair).
1. Narrow is a primitive, not a market.
The Learning Tripod isn’t a research result. It’s a discipline. It means working on all three legs shortly after the PMF milestone, often inventing weird pieces of technology to get them standing.
The first leg: a narrow interaction primitive. One product surface, one interaction unit, one tight feedback event per user session.
Lovable does one thing. Prompt → preview → edit → redeploy. That is the primitive. Not “AI app builder.” Not “no-code.” One repeated action unit: intent becomes running app, user edits, app updates.
Osika calls Lovable “the last piece of software.” Ignore the grandiosity. The useful part is that the product collapses everything into one repeated primitive: prompt, preview, edit, redeploy.
Anton Osika’s GPT Engineer already had 50,000 GitHub stars before Lovable incorporated in late 2024, so the headline “eight months to $100M ARR” needs context. I count from $1M ARR to $100M ARR, and by that measure Lovable is still a GREAT. The important thing isn’t the marketing timeline. It’s the primitive.
Why do narrow interaction primitives matter? Because the narrower the feedback machine, the more focused the signal.
ChatGPT handles every topic in software history. That looks like the opposite of narrow. But measured at the product level, ChatGPT has exactly one interaction primitive: message, receive, thumbs or regenerate. In that sense, the interaction primitive is narrower than that of browser with all its buttons. Every conversation on every topic runs through the same feedback unit.
iFlytek is the inverse. If you don’t follow the Chinese AI market, you probably haven’t heard of them. iFlytek is the country’s speech-recognition champion, publicly traded since 2008, designated a Chinese national “AI Champion” in 2018. They process billions of daily voice interactions. They are genuinely dominant at what they do.
Their market is narrow. Just speech. Their primitives are not. They sell translators, AI tablets, learning machines, in-car voice systems, government systems, industrial models, a bionic robot dog, and recently spun up a semiconductor entity. Thirty product surfaces. Founder Liu Qingfeng admitted it himself: “No single technology will solve the existing problems.”
Twenty-five years of execution, and no single surface became the compounding loop. There was always another surface taking the next round of attention.
Harvey will matter again later. For Leg 1, the point is simple. AmLaw is a narrow market. Legal work is not a narrow primitive. Harvey has been pulled toward multiple feedback units: chat questions, document workflows, end-to-end procedures, workflow builders. A narrow buyer is not the same thing as a narrow loop.
2. The product is the labeling machine.
David Holz founded Midjourney in August 2021 after turning down two Apple acquisition offers. He took zero VC. The Discord bot shipped February 2022:
“If you look at the v3 stuff, there’s this huge improvement… it’s mind-bogglingly better and we didn’t actually put any more art into it. We just took the data about what images the users liked, and how they were using it. And that actually made it better.”
The users labeled it for them.
The parallel to DoubleClick is direct. Midjourney didn’t invent diffusion models. They invented something weirder. DoubleClick didn’t invent ad serving. They invented the DART cookie, a piece of software that could read a user’s behavior across every publisher in a network, in 1996. A click was not just a click. It was a priced action, a relevance label, and a row in the next targeting model.
Today that sounds like “just cookies.” In 1996, it was a real capture invention: a way to observe behavior across publisher surfaces when that was still treated as impractical.
Midjourney? You type “/imagine <prompt>” into a Discord channel (used mostly for gaming). Midjourney returns a 2×2 grid. The grid is not just output. It is the capture mechanism. You press U1–U4 (upscale, “this is my favorite”), V1–V4 (variations, “explore this one”), or reroll (“none of these”). Every click is a labeled preference datapoint tied to a prompt, a user context, and a public channel where other users’ preferences on your image also become training signal.
Hundreds of millions of labeled events per week.
The UI is a labeling machine dressed up as a product.
The critical distinction Leg 2 forces on you: technology invention doesn’t mean novel ML. Midjourney invented the forced-choice interface. DoubleClick invented the cookie that could see across publishers. The invention is in capture, not in the model.
Pandora had the narrow market AND the narrow primitive (recommend music). It even had a form of closed loop. Thumbs-up and thumbs-down adjusted station weights in real time. But Pandora treated those thumbs as station-adjustment weights, not as the central training substrate. The authoritative labels still came from musicologists. The user was allowed to steer. The user was not allowed to become the labeling machine.
What happened in the music recommendation space? Spotify bought The Echo Nest in 2014 for $100M. The Echo Nest was a labeling machine. Its crawlers, audio analysis, playlists, skips, saves, and listening behavior gave Spotify a machine-readable map of taste that Pandora’s hand-labeled genome could not match at speed. One year later, Spotify launched Discover Weekly. By 2018, Spotify had 83 million paid subscribers. Pandora had 6 million.
That is Leg 2: don’t ask whether users can give feedback. Ask whether the product turns feedback into labels the model can actually use.
3. In-session, or it never closes.
Shiv Rao, a cardiologist, and Zach Lipton, a ML professor, founded Abridge in 2018, based on one thing: the clinical note. In the US, the standard tool for capturing clinical notes is Epic, which doctors sign.
Abridge went from PMF to $100M ARR within 18 months. Big clients like Mayo Clinic and Johns Hopkins. A partnership with Epic itself.
“We’re not going to fully automate doctors. We’re going to force-multiply them.” (Rao)
So what’s special about Abridge? It sounds just like voice-to-text.
The capture invention is called Linked Evidence. Every span of every generated note is hard-linked back to the exact transcript segment and audio that produced it (you click play to listen). When a physician edits the draft (changes a word, moves a finding from Assessment to Plan, deletes a line), the edit isn’t just a note change. It’s a labeled correction, tied to the exact audio where the model got it wrong.
Abridge has a narrow primitive (read, edit, sign). The loop closes within one session.
Why is session closure so important? Let’s look at Harvey. Harvey is the legal-industry version of Abridge. Same vintage, AmLaw-100 customers. Strong on Leg 2, weaker on Leg 1 because legal work sprawls across multiple primitives, and blocked on Leg 3 by design.
Harvey’s Trust page commits to zero training on customer data. That’s not a missed opportunity. It’s a feature law firms demand. But it structurally prevents in-session loop closure. So Harvey substitutes: scheduled expert-review sessions, A/B tests on golden datasets, and roughly 350 forward-deployed engineers embedded with customers doing Palantir-style work. Human bandwidth in place of algorithmic feedback.
It works. Harvey got to $100M ARR. In roughly twice the time Abridge took.
Why does in-session matter? Because delayed feedback decays. Ask someone what they ate five minutes ago and you get a label. Ask three days later and you get a story. The same thing happens in products. If the correction happens while the user is still doing the work, you capture the event. If it happens in a review meeting next week, you capture a reconstruction.
In-session does not mean the model retrains instantly. It means the label is captured before context decays. Abridge doesn’t need to update the model in real time. It needs to capture 100% of what it can capture while the source event is still attached to the work.
The three legs aren’t new. None of them is a research breakthrough. DoubleClick was running the loop in 1998. They’d named the business unit Closed-Loop Marketing Solutions before some of the founders shipping AI products today were born. Each leg, on its own, is something a competent product team can name and half-build. What the GREATs in this dataset do is run all three at once, on the same product, in the window where compounding starts to matter.
And the hard part is rarely engineering. Twenty-three pairs in, the pattern got clearer with every one: when a GOOD breaks a leg, the failure is almost always strategic, not technical. iFlytek lost Leg 1 because they sold thirty surfaces to thirty kinds of buyer. Pandora lost Leg 2 because they outlawed the labeling machine on principle. Harvey lost Leg 3 because AmLaw firms won’t let them close the loop. None of those are engineering problems. All of them are business-model problems wearing engineering costumes.
4. The Learning Tripod Test
Pick one product loop and answer:
1. What is the primitive? Not the market. Not the persona. The repeated user action.
2. What captures the signal? A cookie, a linked transcript, a forced-choice interface, an authoring trace. If the answer is “analytics,” you probably don’t have a capture mechanism; you’re just reusing what everyone else does.
3. Does the label happen in-session? If the user has to remember later, reconstruct later, or review in a meeting later, the loop is already slower and distorted.
If you can’t answer all three, you don’t have a labeling machine. You have a product with feedback.
The Tripod, at a glance
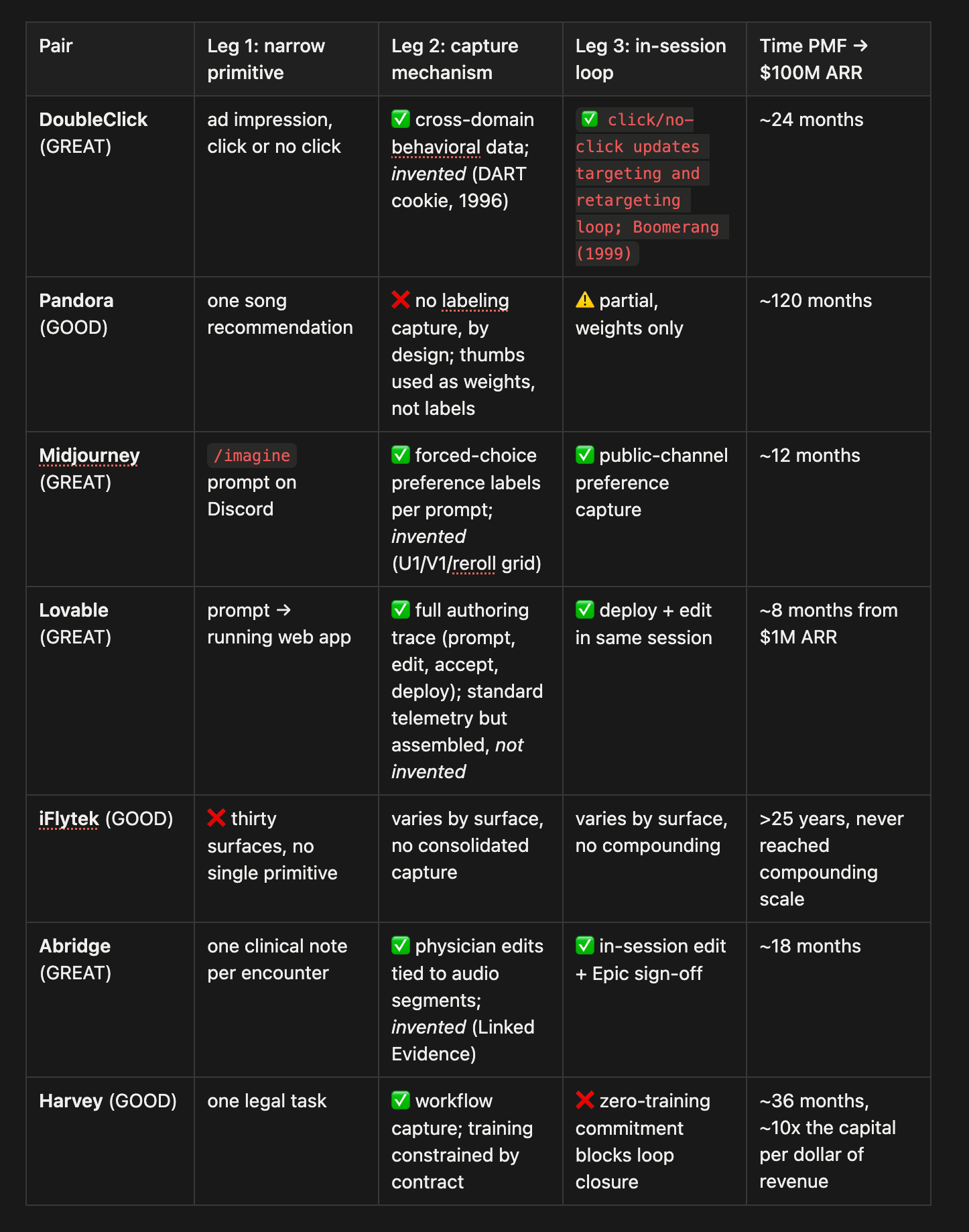
Nothing about these inventions or closed loops is fancy. It’s cookies, links, and weird gaming chat tools. But it works.
Chapter 2: Rotate at 8/10
Why the most rational short-term moves slow you down in five years
“When the facts change, I change my mind. What do you do, sir?” — John Maynard Keynes
“Only the paranoid survive.” — Andrew Grove
George Bell said this in 1999:
“If Excite were to host a search engine that instantly gave people information they sought, the users would leave the site instantly.”
He was explaining why he had just walked away from buying Larry Page and Sergey Brin’s company for $750,000.
Under the cost-per-impression ad regime of 1999, Bell’s logic was tight: better search meant fewer page-views meant less revenue. He did the rational thing and polished the portal. Then the regime changed, and rationality became bankruptcy.
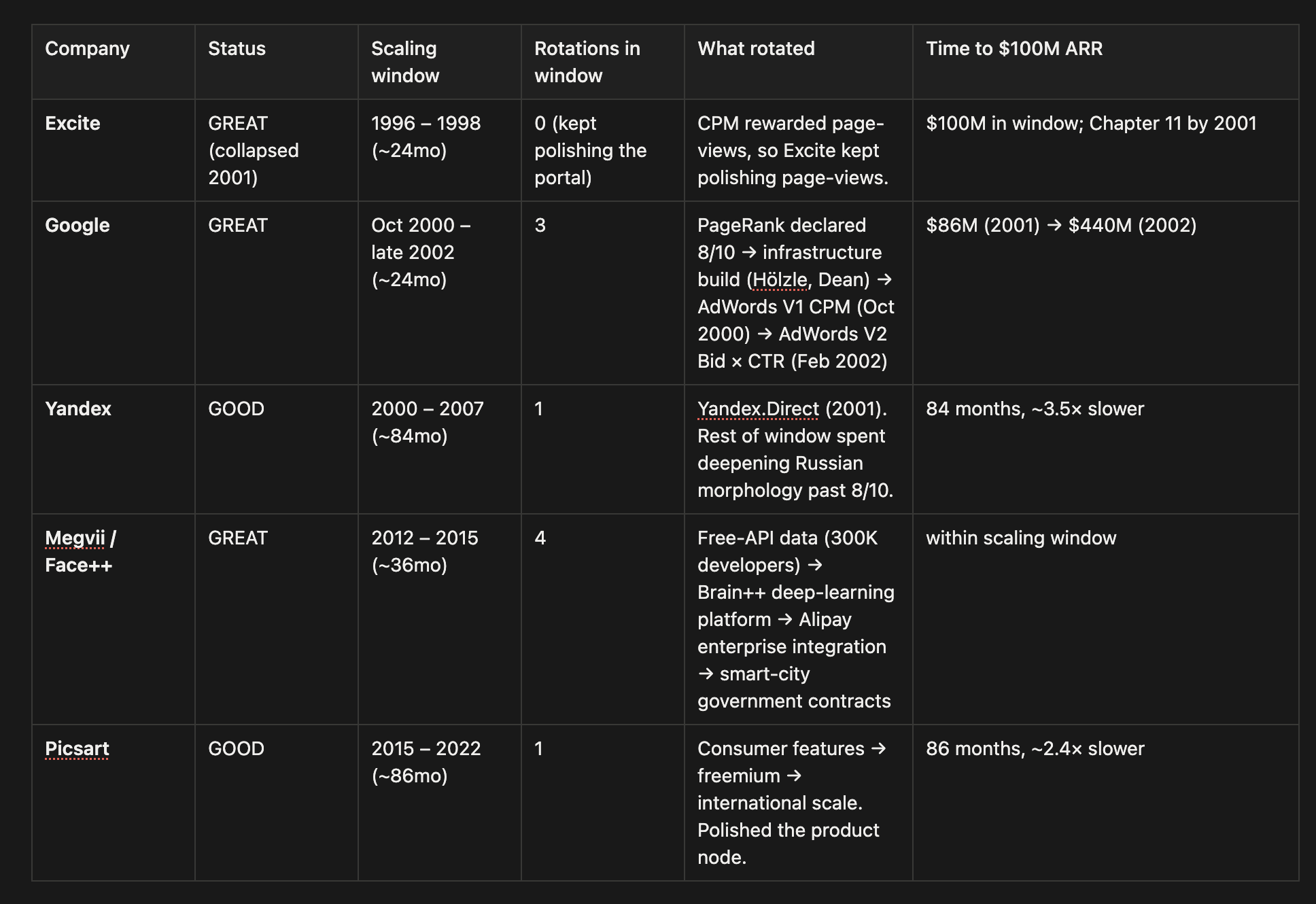
The strange part is that Excite is a GREAT in this study. It hit $100 million in revenue inside the 24-month window that defines the category. Bell ran a winner. Three years later, the winner disappeared.
Excite did not fail because it lacked a flywheel. It failed because the revenue regime told it to keep polishing the wrong node. That is the problem this chapter is about.
Every company in this study has some version of the same flywheel: data → algorithm → product → more data.
In practice, “product” includes the surface, infrastructure, distribution, and monetization layer: whatever turns capability into more usage. Chapter 1 walked the mechanics of how that loop closes. Both GREATs and GOODs build flywheels. So the existence of a flywheel cannot be the variable. The variable is what the company does when one node becomes good enough and the bottleneck moves.
The finding is Rotation Discipline. GREATs rotate at roughly eight out of ten. Once a node is good enough to keep compounding, they move investment to the next constraint. GOODs keep polishing the node current revenue still rewards.
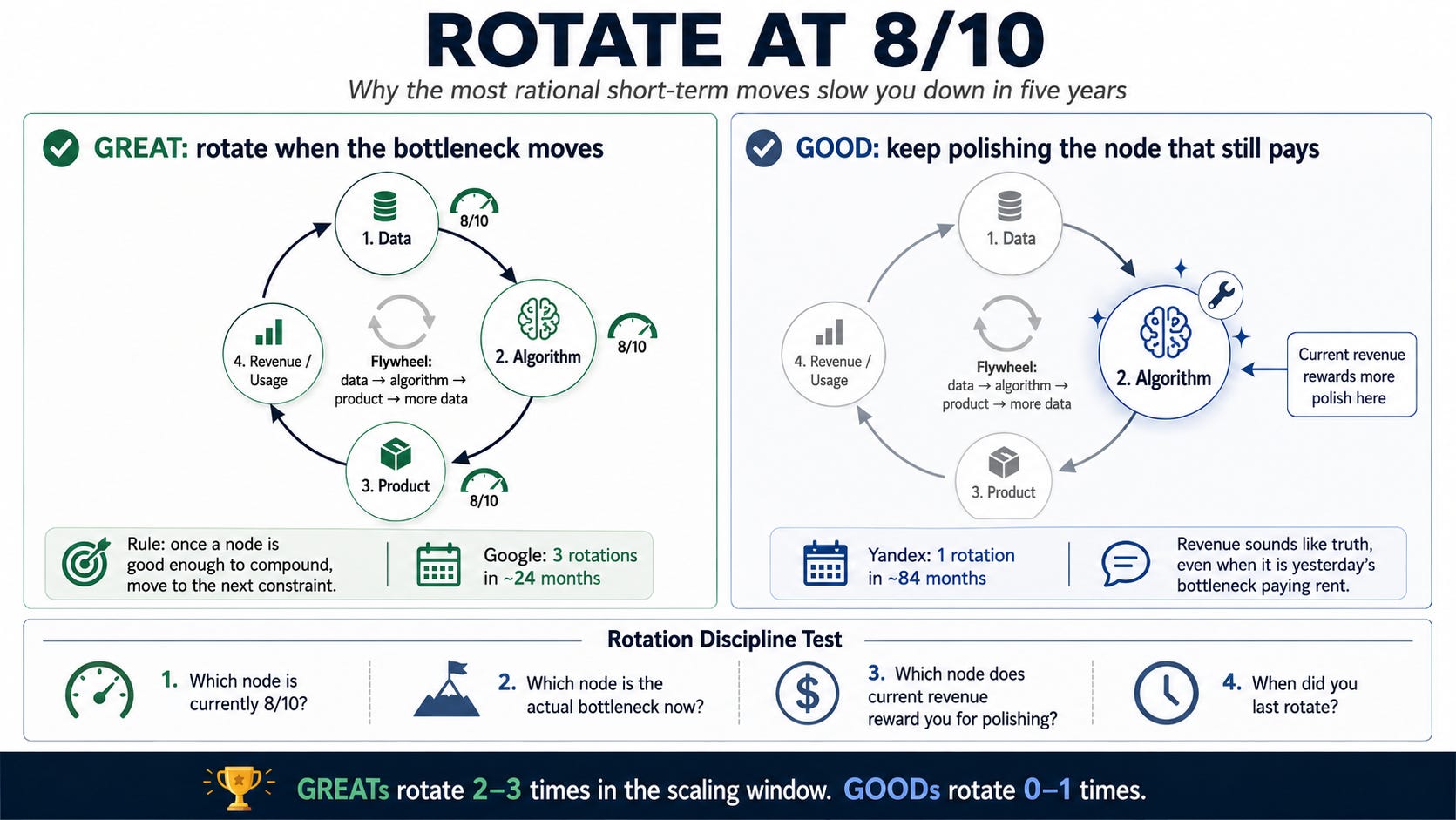
The gap looks small in the quarter. It becomes five years of speed.
In their scaling windows, GREATs rotate two to three times. GOODs rotate zero or one.
1. Google rotated before anything was perfect.
Google’s scaling window runs roughly from October 2000, when AdWords V1 launched and meaningful self-serve ad revenue started flowing, to early 2002, when revenue crossed the $100M run rate. That’s a 24-month window. Here is what Larry Page and Sergey Brin did inside it.
Rotation 1: algorithm → infrastructure (product). PageRank had been their Stanford PhD work. By late 1999 it was shipping and clearly superior to AltaVista and Excite on relevance, but noisy on tail queries and struggling with spam. Rather than polish it further, Brin and Page reallocated investment to the infrastructure needed to serve it at scale: commodity hardware, custom storage, distributed indexing. The binding constraint had moved from algorithm quality to query throughput. The early engineering hires in 1999-2000 (Urs Hölzle, Jeff Dean) were infrastructure hires, not search-quality hires. Through 2000 and 2001 the data-center architecture they built let Google serve orders of magnitude more queries per dollar than AltaVista (yes, that was still a company back then). By 2001 it was handling substantially higher query volume at a fraction of the per-query cost.
Rotation 2: infrastructure → monetization (data). AdWords V1 launched in October 2000 as a CPM product. It tied the flywheel to money for the first time and brought in a new data stream: advertiser behavior on top of user behavior.
Rotation 3: monetization → relevance-ranked auction (algorithm). In February 2002, AdWords V2 shipped with a per-click auction ranked by bid multiplied by predicted click-through rate. The company went from $86M revenue in 2001 to $440M in 2002.
Three rotations in 24 months. None of them waited for the prior node to be perfect (or even great). PageRank was still imperfect when investment shifted to infrastructure. Infrastructure was working but far from finished when investment shifted to AdWords. AdWords V1 was a bridge product when investment shifted to V2. Each rotation happened while the prior node was working but imperfect, somewhere around eight out of ten.
The pattern showed up across the rest of the dataset. No GREAT waited for a single node to reach ten out of ten before moving investment to the next one. GREATs rotated two or three times in their scaling window. GOODs tended to rotate zero or one.
What does 8/10 mean concretely? Gut feel. The moment when the marginal return on further polish on the current node falls below the marginal return on starting the next one. A stable data pipeline. A working algorithm at acceptable depth. A product with enough users that the next data generation will compound. The exact threshold doesn’t matter. The existence of the threshold does. What matters is the feeling that the bottleneck has moved, and the courage to shift fast.
2. GOODs polish the node that still pays.
Yandex stands for “Yet Another iNDEXer,” coined in 1993. Arkady Volozh and Ilya Segalovich built the company around one real insight: Russian-language morphology is much more complex than the stem-and-character methods Western search engines used. So the strategy was obvious and defensible: build the best Russian search algorithm in the world.
And then keep polishing it.
That was not stupid. It worked. The morphology work is still cited in academic NLP papers. Russian advertisers paid for it. Yandex.Direct (their AdWords equivalent, launched 2001) gave every additional increment of morphology a direct revenue signal. The problem is that the same signal kept telling the company to deepen the node that was already good enough.
The outcome: 84 months to $100M against Google’s 24. Inside the scaling window, there was one rotation (Yandex.Direct) and the rest of the investment went into deepening a node that was already past 8/10 by 2003.
Polish the algorithm until you die.
Picsart is the second case, and from the outside it looks like a success story. Founded in Armenia in 2011 by Hovhannes Avoyan, Picsart grew to 45 million MAU by 2014, 100 million by 2017, 150 million by 2024. Their 86-month scaling window runs roughly from first meaningful revenue in 2015 (Sequoia Series A) to 2022. What they did inside the window: kept adding consumer features, moved from free to freemium with Picsart Gold at $4.99/month, scaled their consumer audience internationally, added AI generative tools in late 2022. Each addition made the product surface better. Each addition was something users would pay for. None changed the bottleneck.
Their matched pair, Megvii/Face++, is the counter-example. Megvii rotated through every piece of the flywheel in four visible waves inside their 36-month scaling window.
Wave 1: data rotation. Founded in 2011, Megvii launched Face++ as a facial-recognition API in 2012 and deliberately kept it free through 2013 to amass training data. Every developer call generated labeled image data, which trained better models, which attracted more developers. Within two years the free API had 300,000 developers.
Wave 2: algorithm rotation. By 2015 they had enough data to justify building their own deep-learning stack. Brain++ was an in-house productivity system for training models, designed so they could customize face recognition per customer without rebuilding from scratch. That turned the algorithm from an expensive R&D cost into something they could productize repeatedly.
Wave 3: product rotation. In 2014 Alibaba selected Face++ to implement “pay-with-your-face” in Alipay. This consumed a significant fraction of Megvii’s engineering capacity. A single customer demanded enough scale, latency, and reliability that the team reorganized around making it work. It paid off. The Alipay integration became the reference deployment that won them Face ID contracts with roughly 90% of China’s top 200 internet companies.
Wave 4: new data sources. Starting 2017, at the edge of the scaling window, Megvii pivoted into smart-city contracts where the buyer paid per-deployment in the millions.
Four waves. Four nodes touched. Same 36 months. Picsart spent 86 months polishing one node beautifully and never forced the rotation.
3. Revenue chooses the bottleneck unless you force it not to.
So far this chapter has covered when to rotate: at 8/10, not 10/10, two or three times in your scaling window. That’s half the Rotation Discipline.
A company does not rotate by willpower. It rotates because revenue gives it room to move. Revenue funds more data collection. Revenue funds the ability to pivot between waves. More revenue means more users, which means more data, which means better models, which means more users still. Kill the revenue and the flywheel stops. (If there’s no revenue at all, your flywheel is likely already broken.)
Which means the real question at every quarter isn’t just “which node does the flywheel technically need next.” It’s “which node will someone pay us to work on next.” Those two questions have the same answer less often than founders think.
Google’s rotations inside its scaling window read like they were about technology. The decisive ones were economic. PageRank → infrastructure was a technical rotation. AdWords V1 to V2 was not. Moving from CPM ads to a per-click auction weighted by click-through rate changed the unit of revenue from “impression” to “relevant click.” Under CPM, the most profitable ads were whichever bid the highest, regardless of whether users wanted them. Under Bid × CTR, the most profitable ad was the one the user most wanted to click. Relevance became revenue, mathematically, in a single formula. That’s the move that made the technical flywheel spin faster. Google’s incentive to improve search quality and Google’s incentive to maximize revenue stopped being separate vectors and became the same vector.
The Yandex story shows the same force, pulling the other way. Russian advertisers in 2001-2005 had a specific willingness-to-pay curve. Russian-language queries matched through deep morphological analysis converted better than queries matched by stem-only or character-n-gram methods. Every increment of morphological depth Yandex added had a direct, measurable revenue payoff through Yandex.Direct. Russian advertisers were willing to pay for exactly the node Yandex was already best at. The short-term economic signal Yandex received, every quarter, from revenue data, was “keep polishing morphology, the advertisers are paying for it.” They were right, inside the window of a Russian-language, desktop, 2001-2008 advertising market.
Yandex was rationally forced by the economic incentives. Google used brute force to align the economic incentives with where they wanted to go and make the flywheel turn faster.
The bottleneck a company perceives usually isn’t the technical bottleneck of its flywheel. It’s the economically capturable bottleneck, the node their current buyers are willing to pay more for, inside the monetization regime they’re running. The two are usually different. When they diverge, the company’s perceived pivot is rational under today’s revenue and starves the flywheel the company actually depends on. It’s a simple short-term-versus-long-term mismatch, and humans systematically overweight the short term.
That is the trap: revenue sounds like truth, even when it is only yesterday’s bottleneck paying rent.
4. The Rotation Discipline Test
Pick the flywheel that matters and answer:
1. Which node is currently 8/10? Not the one you’re proudest of. The one where the next quarter of polish returns less than starting work on a different node.
2. Which node is the actual bottleneck now? Not the one with the loudest internal owner. The one limiting the next turn of the flywheel.
3. Which node does current revenue reward you for polishing? This is the dangerous one. If buyers pay you to improve yesterday’s bottleneck, revenue will sound like truth while it slows you down.
4. When did you last rotate? If “never,” you’re Yandex. If “every quarter,” you’re not rotating, you’re thrashing.
For the builders this study is ultimately for, the Rotation Discipline is continuous. AI-native flywheels compound on rotation, and rotation is a decision the builder has to re-make every quarter for the whole scaling window. Not just which node does the flywheel need next, but which node will the current revenue allow them to build. The hardest version of the question: which node would you rotate to if your current revenue did not exist?
Getting those two things mixed up is what took Excite from GREAT at the milestone to Chapter 11 three years later.
The rotations, at a glance
Chapter 3: Stack on the Axis
Why thirty years of unique data became a consultancy, and three years became $29B
“The whole is greater than the sum of its parts.” — Aristotle
“The greatest danger in times of turbulence is not the turbulence; it is to act with yesterday’s logic.” — Peter Drucker
If you showed me the dunnhumby case study without telling me the ending (and the name), I would have called the company a masterpiece. On a November morning in 1994, in a boardroom in Cheshunt, Hertfordshire, a husband-and-wife consulting team, Clive Humby and Edwina Dunn, presented a three-month loyalty-card pilot to the board of Tesco (Britain’s biggest supermarket chain). When Humby finished, Lord Ian MacLaurin said something Humby has been quoting in interviews ever since:
“What scares me is that you know more about my customers after three months than I know after thirty years.”
SIDE NOTE: What’s striking about this is that it starts exactly like the story of Capital One. A small bank, a pair of outside consultants walking in, an internal team that realizes how amazingly valuable their proprietary data could be. Same opening scene. Different ending.
The Clubcard launched eleven weeks later. By 2025 it was handling eighty percent of Tesco’s transactions across twenty-four million UK households. Humby and Dunn wrote the book on what they did, Scoring Points. A decade after that boardroom, at a marketing summit at Kellogg in 2006, Humby coined the line that would become the AI era’s favorite cliché: “data is the new oil.”
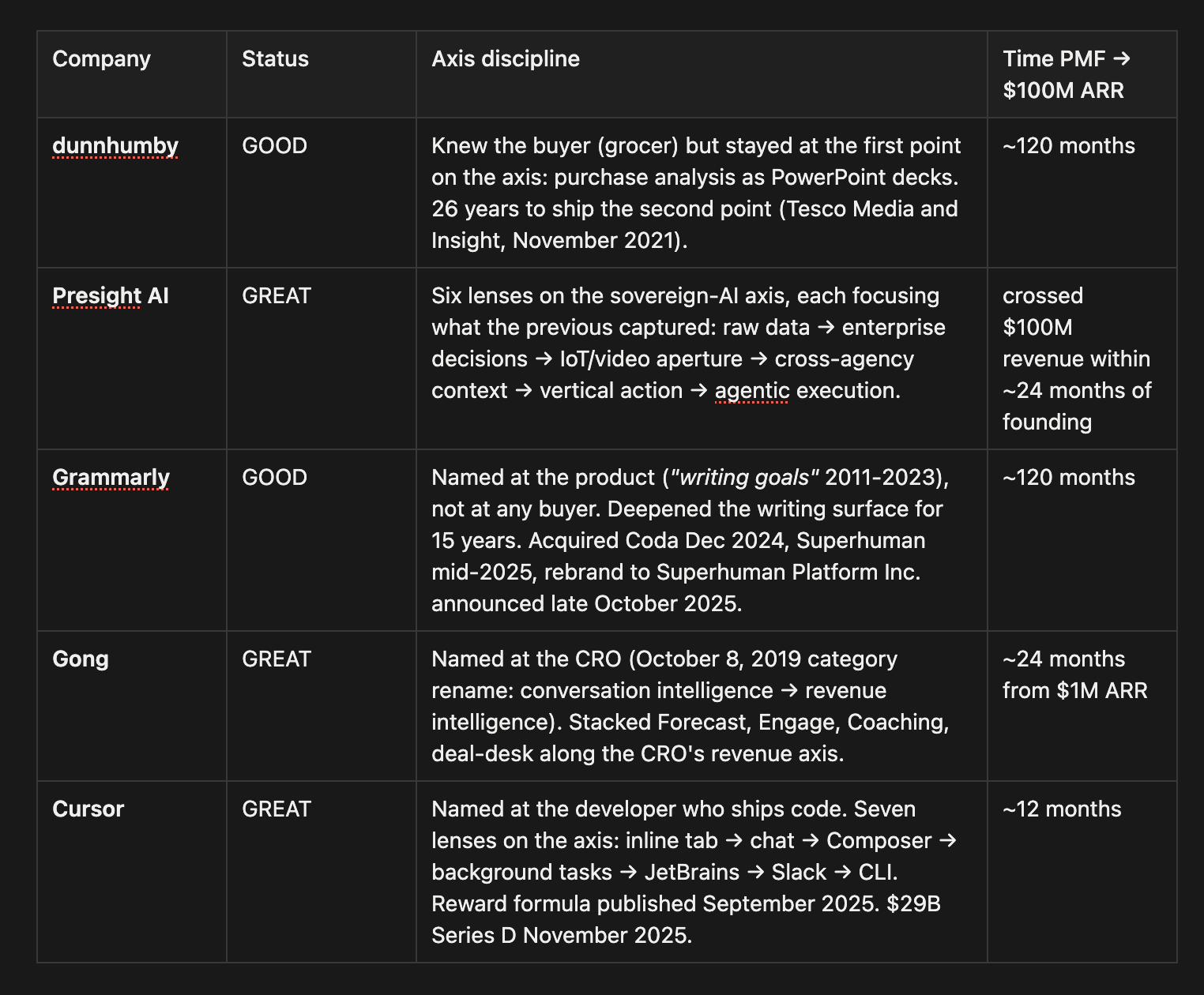
Now look at the research. dunnhumby is in my twenty-three-pair dataset as a GOOD. One hundred and twenty months to one hundred million dollars in revenue. Bloomberg classifies the company as “advisors, analysts and marketing services consultants.” A technology-and-consulting services company, not the compounding software platform the data should have made possible.
The problem was not that dunnhumby lacked oil. The problem was that the oil never moved.
I’ve been operating on a thesis for a couple of years now: get access to proprietary data, pump it all into a competent flywheel, and outstanding returns follow.
Turns out I was wrong.
That leaves an uncomfortable question.
Proprietary data appears in 10 of the 23 pairs in this study. Most of those companies ran a competent flywheel on the data they held. So the data was not the variable. The flywheel was not the variable either.
What was?
For proprietary data, the answer is axis discipline. The GREATs identified the direction their buyer’s economic value actually moves in, then stacked more narrow primitives along that direction, each one its own Tripod. The GOODs found one valuable point on the axis, perfected it, and stayed there forever. 7 of 10 GREATs in the proprietary-data subset ran this discipline. 0 of 10 GOODs did. Off-axis surfaces don’t compound. They just share a logo.
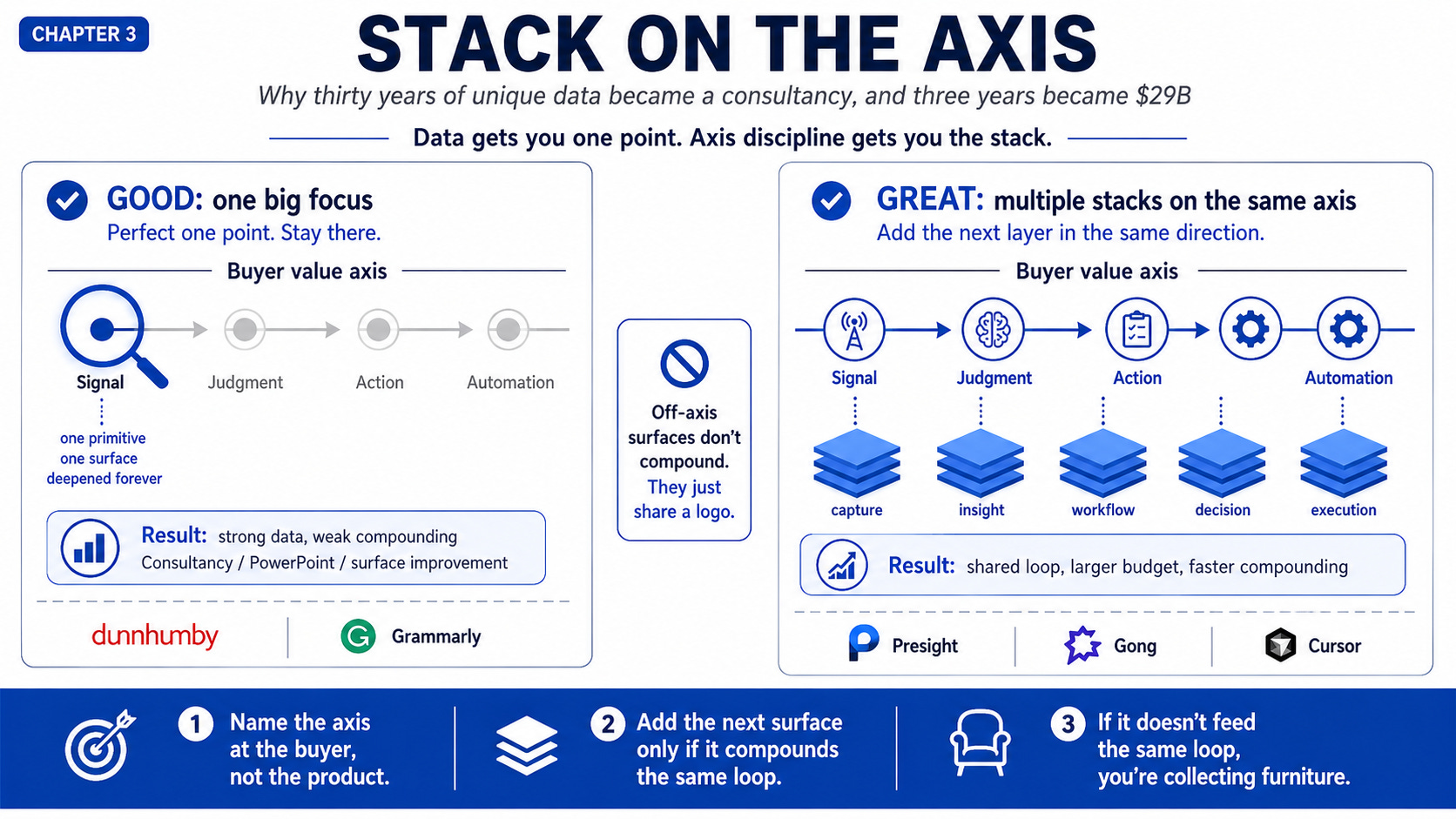
1. Data gets you one point. Axis discipline gets you the stack.
The useful comparison is not another grocer. It is Presight AI, a UAE company that began with the same rare asset: privileged operational data from an anchor relationship. Dunnhumby had Tesco’s checkout. Presight had the UAE government. Different buyers, different politics, different market. Same starting shape:
Exclusive, ambient access to operational data from a single anchor relationship. For dunnhumby in 1995, the anchor was Tesco’s checkout. Every transaction, every customer, every basket, via the Clubcard. For Presight in 2020, it was the UAE government. Data streams from ministries across defense, finance, energy, and human capital.
Both companies built a flywheel on the data. Both ran the Tripod from Ch 1 with reasonable competence. The capture was ambient. The loops closed. The primitives were narrow.
The difference shows up only when you ask what they did next.
Dunnhumby’s customer was a grocer. A grocer’s economic value moves in a recognizable direction: purchase data leads to relevant offers, relevant offers lead to personalized engagement, personalized engagement leads to ad targeting, ad targeting leads to operational decisions about what to stock and where. That direction is the grocer’s axis of value. Each successive point on it is worth more to the grocer than the one before, because each one moves closer to a decision the grocer can monetize directly.
Dunnhumby found the first point on the axis (purchase data analysis) and froze there. They built that one point beautifully, deepened it for two decades, delivered the work as PowerPoint decks. PowerPoint decks are where proprietary data goes to become someone else’s strategy. The first advertising product built on Clubcard data, Tesco Media and Insight, shipped in November 2021. Twenty-six years after the Clubcard went live. By the time dunnhumby moved to the second point on the axis, the market had built its own versions of points three, four, and five.
Presight did the opposite. In roughly four years, it stacked six lenses on the sovereign-AI axis.
First, it turned raw agency data into analytics-grade signal (TAQ). Then it turned that signal into enterprise decisions (Vitruvian and Connect, the Enterprise AI Suite, July 2024). Then it collected more data with IoT and video telemetry (IntelliPlatform). Then it let signal cross agency boundaries (DataHub). Then it focused the shared signal into vertical agency primitives: policing (AI-Policing Suite), emergency response (LifeSaver with NCEMA), media regulation (Unified Media AI Platform with the UAE Media Council).
Finally, with ENERGYai, it pushed the stack from decision support toward agentic execution in energy operations: lower costs, lower emissions, more automated decisions.
The product names matter less than the sequence. Each lens focused what the previous one captured.
Dunnhumby kept improving one lens. Presight kept adding the next lens on the same line.
Edwina Dunn, looking back in 2019 on the industry she and Humby helped create: “Dunnhumby was rear view mirror, so too is the data science across most of the industry. Companies tend to look only at their own data.”
Ch 1: build the Tripod on a narrow primitive. Ch 3: stack more primitives along the axis of customer value, each one its own Tripod, all on the same direction. Dunnhumby had one magnifying glass at one point. Presight had a sequence of magnifying glasses, each focused on the same line, each one multiplying the focus of the one before it.
2. The right axis is named by the buyer’s budget, not your product surface.
The hard part of the axis isn’t recognizing that you should stack on one. The hard part is naming the right one. The axis lives where the budget lives, which is rarely where the product currently lives.
Products have surfaces. Buyers have gravity. Name the axis at the surface and you keep asking “how do we make writing better?” Name it at the buyer and you ask “who pays when communication fails, deals slip, forecasts miss, or decisions slow down?”
Let’s compare Grammarly with Gong.
Both companies started with the same kind of asset: ambient access to the substance of professional knowledge work, captured at scale, by default, as people did the work.
Grammarly: a writing assistant inside the browser, the email client, the document, the messaging app. One million daily active users by 2015. Thirty million by 2020. If you wanted to know what knowledge workers actually wrote, not what they said they wrote, Grammarly was the one company on earth that knew.
Gong: a meeting bot inside enterprise sales calls. The conversations that actually decided whether deals closed, captured by a bot that joined the call automatically. By 2021 the company was valued at $7.25 billion. By 2025, over 4,000 customers.
Two companies. Same starting assets. Very different choices about whose axis they were on.
Eilon Reshef, Gong’s CPO, has told the design-partner story a few times now. Twelve sales teams in 2015–2016 trying out an early version of the product. They started complaining that the bot wasn’t joining every call, just the ones the rep manually flagged. Gong hadn’t built that yet. They built it. Once they implemented universal recording, the design partners went quiet, “happily relying on the tool for every sales conversation.”
That’s the first primitive locked in. The bot joins by default. Recording is the norm. Opt-out is the exception. The captured calls weren’t just transcribed. They were rendered into the seller’s own workspace as judgments. A flag in Salesforce: this deal is at risk because the prospect’s CFO hasn’t spoken in the last two calls. A coaching note: your three top sellers all ask this question at minute fourteen, and you don’t. The seller acted on the judgment before the next conversation. The next conversation generated more data. The model retrained per-deal, daily.
Two primitives on the axis. Both about the seller closing the next deal.
The third move came on October 8, 2019, and you can read Udi Ledergor’s first-person account of it on his blog. Gong’s marketing team announced the company was leaving the existing category, “conversation intelligence,” and creating a new category called “revenue intelligence.”
This sounds like positioning. Annoyingly, it was strategy. It named the axis at the buyer.
Conversation intelligence sold to sales operations, individual sales reps. Revenue intelligence sells to the Chief Revenue Officer, where budget is millions. The product was substantially the same. The axis Gong was now stacking on was different: the CRO’s axis runs through forecast accuracy, deal velocity, and quota attainment, and every product Gong shipped after October 2019 (Forecast, Engage, Coaching, the deal-desk tools) landed inside that scope because they’d named the axis where the larger budget lived. Gartner picked up the category about a year later.
Now Grammarly.
The frame Brad Hoover settled on as CEO in 2011, and stayed inside until 2023, was writing goals. Not communication outcomes. Not the actions writing leads to. Not what someone does with the email after it’s drafted. Writing. Goals.
You can see the frame in the words Hoover used for fifteen years. From the IVP profile, recounting how the early team aligned in 2011: “we coalesced around a vision of building Grammarly into a broad-based communication assistant that went far beyond spelling and grammar, enabling people to fully accomplish their writing goals.“
The frame is writing goals. It’s a product description, not a buyer description. It doesn’t ask whose budget cares about better writing, or who would pay more for that writing to do something specific (close a deal, prevent a misunderstanding, get a decision through faster).
What got built reflected the frame. Native apps for Windows and Mac in 2017. Mobile keyboards in 2018. Tone detector in 2019. Each one a deeper, more accurate version of “help people write better in the place where they’re writing.” None of them moved up the value chain to the manager who pays for better team writing, or the operations leader who pays for fewer miscommunications, or the chief of staff who pays for faster decisions.
GrammarlyGO, the first generative-writing feature, the first product that could compose something rather than fix something, shipped in March 2023. Four months after ChatGPT shipped. The CEO who steered the writing-assistant frame for twelve years, Hoover, stepped aside the same month. Coda acquisition: December 2024. Superhuman acquisition: mid-2025. Corporate rebrand to Superhuman Platform Inc.: announced late October 2025.
Grammarly did not miss the future because it lacked data. It missed the buyer.
Name the axis at the product and you keep improving the surface. Name it at the buyer and you move toward the budget. Gong did the second move in October 2019. Grammarly did the first move for fifteen years, then realized it had to acquire its way out.
3. Surfaces compound only when they share the same axis.
This is where axis discipline becomes dangerous to copy. From the outside, it looks like “add more surfaces.” Inside the loop, it is the opposite: add only the surfaces that feed the same buyer outcome.
Cursor is the contemporary version because every new surface touches the same buyer outcome: developer ships code (not writes code). Inline tab captures micro-acceptance. Chat captures intent. Composer captures multi-step delegation. Background tasks capture unattended work. Slack and CLI move the loop outside the IDE. Seven surfaces, same axis, shared reward loop.
In September 2025 Cursor published the formula behind that loop on their engineering blog: accept gets +0.75, reject gets −0.25, weights roll every ninety to one hundred and twenty minutes on four hundred million requests a day. They were not worried about anyone copying it, because the formula travels but the axis discipline does not. dunnhumby could ship the same formula tomorrow and it would land on PowerPoint decks for grocers. Grammarly could ship it and it would run on the writing surface for another decade. The math is portable. The choice of which surfaces to stack so signal flows between them is not.
Here is the Axis Discipline Test. Pick one product line (based on proprietary data) and answer it honestly.
1. Who is the buyer whose budget gets bigger when this works? Not the user. Not the team that likes you. The buyer.
2. What direction does their economic value move in? From signal to judgment? From judgment to action? From action to automation? Name the line.
3. What was the last surface you added? Did it compound the same loop, or did it just share the logo?
If it does not feed the same loop, you are not stacking. You are collecting furniture.
Humby called data the new oil in 2006. Twenty years later, dunnhumby is a consultancy because the oil never moved. Cursor is a billion dollar coding IDE because it did.
Companies referenced in this chapter
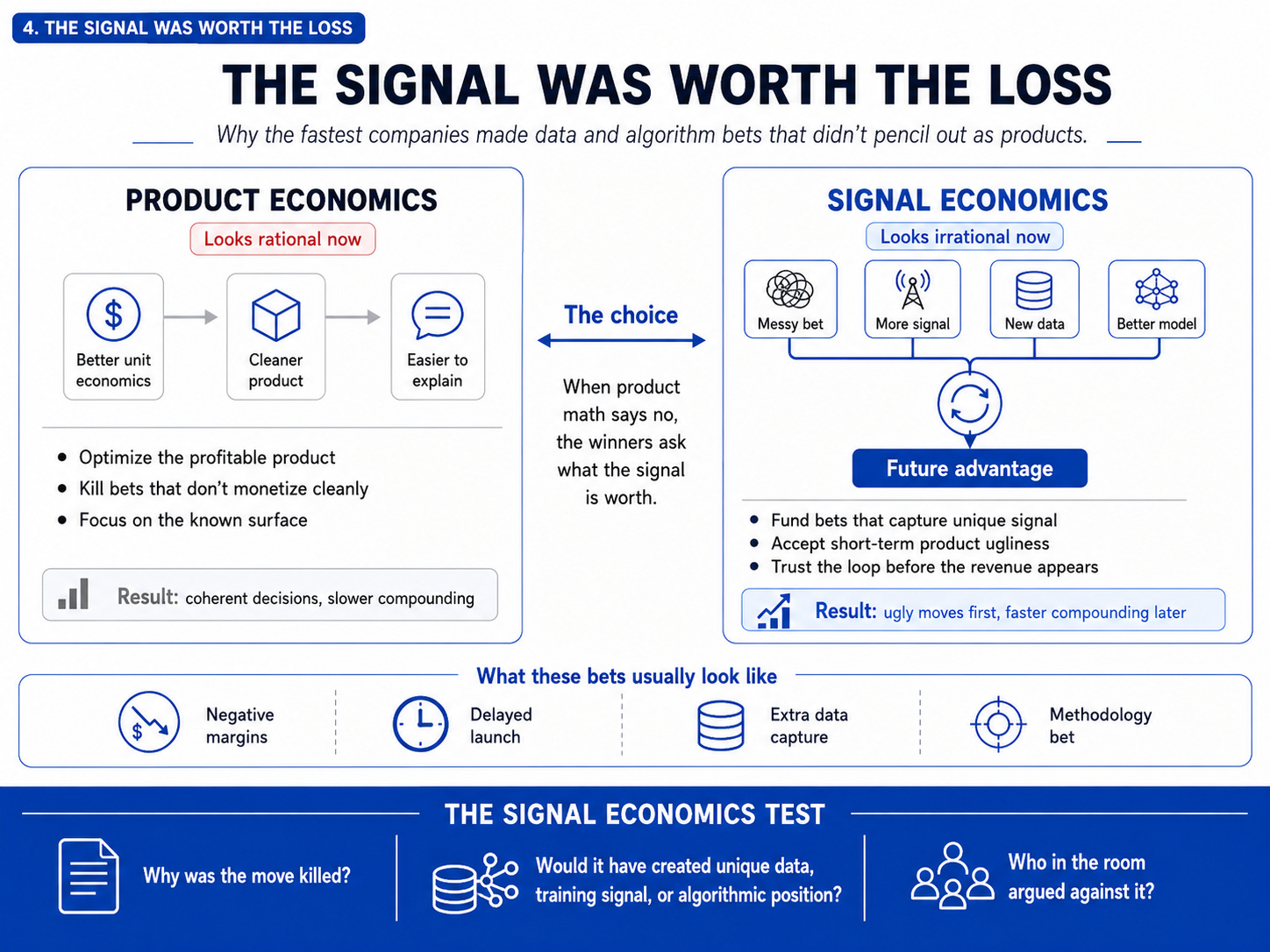
Chapter 4: The Signal Was Worth the Loss
Why the fastest companies made data and algorithm bets that didn’t pencil out as products.
“Character is destiny.” — Heraclitus
“All happy families are alike; each unhappy family is unhappy in its own way.” — Tolstoy
Meitu had appeared in two earlier chapters. Both times I thought I had explained it. Both times I kept coming back to it in my notes.
The company was listed on the Hong Kong Stock Exchange in December 2016 with ninety-five percent of revenue coming from selling smartphones at a loss. Read that again. The IPO prospectus of a publicly traded company was carried by a hardware line that lost money on every unit. Under product economics, the company shouldn’t have existed.
Then it licensed the phone brand to Xiaomi for a thirty-year royalty stream. Then it disclosed a forty-million-dollar Bitcoin and Ether treasury position in March 2021. Then it sold the crypto in 2024 for a gain larger than its full-year operating profit and paid out a special dividend. Cai Wensheng, the founder, later expressed regret about the crypto position. Not because they lost on it. Because they won, and the win wasn’t strategic. The focus, he said, was now on AI.
The founders, Cai Wensheng and Wu Xinhong, are in their forties. You cannot find either of them on LinkedIn. The website still looks like 2014.
The more I studied Meitu, the less it looked like strategy and the more it looked like a company that had decided product economics was someone else’s problem.
A Meitu, for the rest of this chapter, is a company whose winning moves were locally stupid as products and rational as data bets. The phones lost money. The face-image dataset they captured did not. The first half of that sentence is what most builders see. The second half is what made this company.
So how many more companies in this study made moves that looked obviously wrong as products and turned out to be data or algorithm bets in disguise?
Holy shit, lots.
DoubleClick paid $1.7B in 1999 to merge anonymous cookies with offline household profiles, triggering an FTC investigation. That wasn’t a marketing play (would’ve been a pretty terrible one). It was a bet that fusing the two datasets would matter more than the potential backslash and legal troubles.
Anthropic held its flagship model back from public release for seven months while OpenAI ate the consumer market.
Cursor ran negative gross margins on inference for an entire year. That wasn’t a pricing mistake. It was the cost of capturing four hundred million daily keystrokes of accept/reject signal.
Manus shipped a model wrapper as a stealth product in early 2025 with invite codes trading hands at six figures.
Three things kept showing up.
The move never made sense alone. It made sense as part of a bundle.
The slow side saw it, reasoned about it, rejected it on product logic, and lost anyway.
The disposition that produced the bundle wasn’t strategic. It was the founder’s tolerance for running data and algorithm bets the product math wouldn’t approve.
1. The move made no sense as product. It made sense as signal.
Between 2012 and 2014, Meitu didn’t just launch one strange product. They launched a sprawl of free apps: BeautyCam in April 2013, Meipai in May 2014, BeautyPlus in April 2013. All generating face-image data at zero direct revenue. None with any clear monetization path. While that app sprawl was running, they launched the Meitu Kiss smartphone at RMB 2,199, a loss-making phone aimed at women selfie users.
At the launch, Cai Wensheng framed the strategy: “the best structure for mobile internet businesses is software + hardware + cloud.” The apps captured the faces. The phones, sold below cost, pulled the apps’ users onto a controlled hardware surface that captured higher-quality face data and behavioral signal. The cloud layer fused both streams. Hardware revenue ramped from 59.7% of total in 2013 to nearly 90% by 2015. Every dollar of that hardware revenue was subsidizing a data-acquisition channel.
The matched-pair company, Lightricks, founded in January 2013 in Jerusalem by five Hebrew University PhD students, did one thing through the same period: subscription mobile creative apps. Facetune launched March 2013, Facetune 2 with the subscription pivot in 2016, then Enlight, Photoleap, Videoleap. Thirteen years of clean subscription compounding to a $1.8B Series D in September 2021. Beautiful product economics. The unit math worked at every stage. The founders of Lightricks could explain every decision in a single sentence.
Lightricks ran the rational moves. They won inside one regime. In February 2026 they had to split the company in two to chase the AI multiple the subscription business never gave them a reason to build.
My guess: Meitu would not have needed a clean business-unit split to chase the AI multiple. It would have just chased it. Lightricks needed the move to make organizational sense first. That is the difference between product economics and signal economics in one sentence.
Cleaner companies run fewer ugly bets. That is why they look better in the board deck. It is also why they get fewer chances to discover a combination whose value only exists after the pieces touch. A signal bet rarely pencils out alone. It pencils out as part of a bundle.
Seventeen years earlier, DoubleClick ran the same pattern. The DART cookie read behavior across publishers. DART for Publishers and DART for Advertisers put the company on both sides of the ad market. Then DoubleClick bought Abacus and tried to fuse anonymous browsing with offline household profiles. The FTC investigation arrived by early 2000. Google still bought DoubleClick for $3.1B in 2007. The move looked ugly as product and dangerous as PR. It made sense as signal.
Two GREATs, seventeen years apart. Both running multiple bets at the same time. Both winning a combination they couldn’t have specified in advance, because the value of the combination only existed in signal space, not in product space. The harder question is why the slow side, watching the whole time, wouldn’t make those bets.
2. The slow side wasn’t asleep. It was running the wrong economics.
Aidan Gomez sat down with McKinsey in 2024 and explained, fluently and on the record, why Cohere wasn’t building a consumer product. “What has helped us succeed in the enterprise world is the fact that we’re only focused on enterprise. We’re not trying to build a consumer service at the same time as we’re trying to build this enterprise platform.”
Clean and rational. It’s also the answer of a CEO whose company would cover the same revenue ground from 2023 through 2025 that Anthropic covered in twelve months. $87M ARR in January 2024 to $1B by December.
Anthropic spent the years leading up to and through that window doing several things that violated startup common sense.
They held Claude back from public consumer release until July 2023, roughly seven months after ChatGPT. They published the Responsible Scaling Policy in September 2023, a public commitment to pause development at safety thresholds, in writing, in front of investors. They ran on Constitutional AI, the research that let them substitute cheap RLAIF for the expensive RLHF labor pipeline OpenAI was paying for. A methodology bet that, if it worked, replaced an entire vendor category of human-labeled training data.
Cohere watched all three moves and chose not to make any of them. Gomez can tell you exactly why. He’s right that running a consumer service while building an enterprise platform is hard. He’s right that focus is a real advantage. He’s running product economics, perfectly executed. And product economics under regime shift produces the wrong answer.
That’s the uncomfortable part. The slow side isn’t asleep, isn’t outflanked, isn’t missing the memo. They’re thinking. They’re making coherent strategic arguments. They’re losing anyway, because the strategic arguments they’re making are correct under product economics in a moment when the true focus should be signal economics.
Cursor went from $1M ARR to $100M ARR in twelve months between January 2024 and January 2025. In that year, Cursor forked the entire Visual Studio Code IDE rather than ship a Microsoft-style extension, ran inference at negative gross margins to capture every keystroke, trained a custom Tab autocomplete model on accepted/rejected suggestions, and acquired Supermaven in November 2024. Aman Sanger had articulated the rationale on Latent Space in August 2023, before Cursor had any meaningful traction: “in the long term, you’re going to need to design just a very different UX that the extensions don’t give you.” He wasn’t talking about user experience. He was talking about signal architecture. The UX matters because it produces the training signal, not because users like it.
The matched pair, Suno, covered comparable revenue ground in the same window with episodic batch generation and a polished surface across web and mobile. No continuous in-product capture loop. Mikey Shulman went on 20VC in January 2025 and gave his own version of the answer: “At some point, I don’t know if it’s version 4 or version 5, there will be a last model release that is released as a model. Everything else is just product releases.” It’s a reasonable theory of where value lives. It’s also wrong if signal is the unit. Suno is running product economics, beautifully. Cursor is running a different game.
In both pairs, the slow side could articulate exactly why they weren’t doing what the fast side was doing. The articulation was correct under product economics. The moves weren’t strange because the slow side missed something. They were strange because they violated a logic the slow side correctly understood.
Coherence under the current economic regime is what gets you the wrong answer at exactly the moment the regime changes.
3. Disposition shows up as which economics you trust.
“when your user base is big enough, you can do anything.” (Cai, CEO of Meitu, 2017)
It’s not a strategy. It’s not even an argument. It’s a personality. Whatever Meitu happens to be doing on a given Tuesday (selling phones, holding crypto, licensing IP to Xiaomi, pivoting into enterprise AI), Cai is the kind of person who will keep doing more of it on more surfaces until something stops him.
Zeev Farbman at Lightricks said something different and just as durable. November 2018, deep into Lightricks’ subscription compounding: “this field of creativity lends itself well to the exciting, and in many ways, new business model of consumer mobile subscription.” That’s also not really a strategy. It’s a description of what Farbman finds exciting: subscription mobile creative apps, specifically. He’s optimizing for subscription unit economics, which is a perfectly defensible product frame. Lightricks spent the next eight years inside that frame until February 2026, when they had to surgically split the company in two to chase a multiple they hadn’t built. Farbman wasn’t wrong about subscription. He was right about it for a decade.
The cleanest explanation I can give is uncomfortable: The pattern is which economics the founder trusts when forced to choose between them. (Product economics, or signal economics?)
It’s a simple question for YOU: If you’re confronted with a choice between building a better more profitable product, and an opportunity to gain more signal into an unknown space. Will you go with the likely good known product? Or will you go with the signal, and trust that, over time, it will lead you to even more profitable products? It’s easy to say “but” but those founders didn’t say but. They choose the signal, even if times are hard, not just in the good times when they have “money to throw around on experiments.”
This is also the answer to what the previous three chapters were really about. The Tripod, the Rotation, and the Axis are not three frameworks. They are three things a signal-economics disposition will do.
The labeling machine costs product surface area.
Rotating at eight-out-of-ten costs short-term unit economics.
Stacking on the axis means adding surfaces that don’t pencil out individually.
A founder who trusts product economics will not run any of them. A founder who trusts signal economics will run all three without being told.
Whether their disposition would have been right for a different moment is a question the dataset can’t answer, and one the founders themselves probably couldn’t either.
Here is the Signal Economics Test. Pick one move your company killed in the last six months and answer honestly.
1. Why was it killed? If the answer is “the product math didn’t work,” keep reading. If the answer is “it was illegal” or “we didn’t have the cash,” stop here. This test isn’t for you.
2. Would it have produced data, training signal, or algorithmic position your competitors could not buy later? Not “better user experience.” Not “improved retention.” A dataset, a feedback loop, or a methodological position someone else would have to spend years rebuilding.
3. Who in the room argued against it? Listen to them. They may be right. But in this study, the slow side often sounded most intelligent right before it lost.
No table this time. The founder-disposition pattern shows up across the other chapters. The point is simpler: when product economics and signal economics disagreed, the GREATs trusted the signal.
The CFO usually had the cleaner slide. The winner usually had the uglier loop.
Chapter 5: Stacking the Boring Parts
Why the GREATs run all four boring parts of data-centric AI. The GOODs run two and call it strategy.
“Amateurs talk strategy. Professionals talk logistics.” — military proverb (often attributed to Omar Bradley)
“In God we trust. All others must bring data.” — W. Edwards Deming
You already know the Cohere/Anthropic gap.
By now, you also know it wasn’t one thing.
It wasn’t just the product surface. It wasn’t just the buyer axis. It wasn’t just signal economics. It wasn’t just the willingness to do locally absurd things.
Those were the visible decisions.
This chapter is about the machinery underneath them: the boring data system that made the decisions compound.
Anthropic did not just have a better model. It had a better failure machine.
Cohere ran pieces of that machine. Anthropic ran the whole thing.
And that is what makes this chapter irritating: the machine was not hidden.
Andrew Ng popularized the phrase data-centric AI in 2021. Karpathy had made the data-as-leverage argument earlier in his 2017 “Software 2.0” essay. By 2024, the field had a whole tooling and workshop ecosystem around data quality, labeling, governance, and evaluation. Fine. The operating questions were older than the literature.
In fact, they were already visible in 1999, inside a directory company with two hundred editors. The editors were not called labelers. They were called ontologists.
“The Looksmart directory is professionally edited by Looksmart ontologists (experienced editors who specialize in content classification and organization) into 26,000 categories and the keywords”
The four questions are boring enough to miss:
What counts as right?
How fast does right change?
Which errors decide tomorrow’s data?
Who is allowed to label?
Across the dataset, the GOODs usually had one or two of these. The Verbits and the Uniphores both had labeling pipelines. The Anthropics and the Coheres both retrained against feedback. The GREATs answered all four on the same loop.
The gap isn’t awareness. It’s stacking.

1. LookSmart was already running the boring stack in 1999.
In 1999 a directory company called LookSmart went public on NASDAQ at a billion-dollar valuation on the back of two hundred paid professional category editors and an Editor-in-Chief. The directory they curated was the substrate behind a meaningful fraction of MSN search traffic. Microsoft was paying them thirty million dollars up front and five million a year. For accuracy.
What counts as right? The editors knew. They described their duties to Traffick in October 2000 as “ontology and content oversight.” Ontologists. Not labelers. After the October 2000 Zeal acquisition, LookSmart added a managed volunteer corps gated by a quiz on the same editorial standard, with tiered admission and a mentor program. The apparatus existed to make sure volunteers labeled to the same standard the paid editors did.
How fast does it change? The contract forced the answer. Editor review of new submissions in three business days. Listings live on MSN within a month.
Which errors come first? Microsoft told them. From LookSmart: “the test results will affect Microsoft’s decision to renew the distribution agreement, and whether to continue to distribute some or all of our paid listings after the agreement expires.” A paying customer running A/B-style quality comparisons. With the renewal as the prize. The errors Microsoft flagged were the errors LookSmart fixed first.
Who labels? Professional category editors. Domain judgment applied by people whose job title named the domain.
Four questions, one loop, running together, in 1999.
BizRate, founded the same year (later renamed Shopzilla after a 2004 acquisition), ran the opposite playbook on the same go-to-market. Same portal-licensing strategy, same era, same buyers. The substrate was different. ShopRank ran a patent-pending algorithm over machine-aggregated product data and returned shopping results in twenty milliseconds. The labeled-feedback channel was a million consumer reviews per month, but the reviews were structured for merchant ratings, not for refining what got listed in the first place. There was no editorial standard, because there were no editors. The largest hiring pool was engineers.
Both companies were running data-centric AI before anyone called it that. LookSmart hired experts to apply a defined standard on a tight cadence with errors fed back through their paying customer’s own quality tests. BizRate ran an algorithm. LookSmart reached one hundred million dollars in revenue in twenty-four months. BizRate took sixty.
2. Four questions, one loop.
Watch what just happened. LookSmart didn’t have a research breakthrough. It had four answers applied together on the same loop.
What counts as right? A defined standard of correctness applied by humans at scale. A working document that tells a labeler whether output X is acceptable for use case Y. Not a research paper. Not a tone-of-voice deck.
How fast does it change? Days, weeks, not quarters. The loop closes faster than the market can write a competing playbook.
Which errors come first? The hardest, most surprising failures get routed back into the next training cycle before anything else. The GOODs train on whatever data arrives next.
Who labels? People with substantive domain knowledge. Not Mechanical Turk. Not customer staff. Not whoever happens to sit inside the customer workflow.
The GOODs do data-centric AI as a function. The GREATs do it as an operating system.
3. Verbit owned the correction loop. Uniphore rented the workflow.
Two and a half decades after LookSmart, the cleanest contemporary illustration is a pair of transcription companies.
Verbit was founded in Tel Aviv in 2017. A transcription company that reached $100M ARR inside the twenty-four-month scaling window. Their matched pair, Uniphore, was founded at IIT Madras in 2008 and took roughly ninety-six months to cover the same ground. Both companies were doing what looks superficially like the same work: taking enterprise audio, turning it into accurate text, getting paid for it.
Verbit answered all four questions.
What counts as right? Style guides for the transribers by domain. Legal for court depositions. Medical for clinical recordings. Captioning for compliance work.
Who labels? 22,000 freelance transcribers at the Series B milestone, growing to 35,000 plus 600 professional captioners by Series E. Specialists, not commodity labor, at twenty-four to thirty cents a minute.
How fast does it change? Corrections flowed back into the self-learning speech recognition models continuously. The model retrained on its own outputs, edited by experts.
Which errors come first? Funnily, Verbit even invented a patented technology to do the error routing: When a transcriber edits an audio segment, the segment is scored for how surprising the correction was, minimum-Bayes-risk and perplexity, and the high-surprise corrections get routed back to retraining first.
That last part is the tell. Verbit was not training on whatever audio arrived next. It was training on where the model was most wrong.
Uniphore looked like the cleaner SaaS company. API-first. Close to contact centers calling a ton. Founder Umesh Sachdev on Bloomberg Tech Disruptors: “Uniphore has delivered these outcomes by packaging AI solutions as software-as-a-service.” No rip-and-replace. Industry-specific small language models built per engagement through partnerships. Five technology stacks bolted on through M&A.
Sensible. Enterprise-friendly. Easy to put in a board deck.
But Uniphore didn’t own the same loop. No central labeling marketplace. No public domain-by-domain standard. No visible cross-customer failure-routing system. No expert labeler pool applying one standard at scale. The labeling, when it happened at all, happened inside whoever’s call center platform the customer was already running, by whoever that platform employed.
Verbit owned the correction loop. Uniphore rented the workflow. That’s the gap.
4. Anthropic made failure visible. Cohere made failure private.
Cohere’s deployment posture is not a mistake. It is the product a regulated enterprise buyer wants. Keep the model near the customer’s data. Don’t leak anything. Don’t centralize anything. Deploy in VPCs, on-prem, air-gapped if needed. The company wins regulated-industry deals on exactly this commitment: RBC, Ensemble Health, Fujitsu, LG, Bell Canada, the UK and Canadian governments.
Great product economics. Terrible shared failure list.
This is the link to the previous chapter. Cohere’s deployment posture isn’t a strategy mistake. It’s what running product economics, perfectly executed, looks like at the architecture layer. The disposition I named in the last chapter shows up here as code. The same founder who told McKinsey “we’re only focused on enterprise” is the founder whose architecture makes the shared loop much harder to close.
The four questions assume the loop closes globally. Cohere’s commercial choice makes sure it closes locally, if at all.
Anthropic answered all four.
What counts as right? The corpus of RLHF instructions plus the published Constitutional AI principles. The principles function as a self-applied standard the model uses to label its own outputs at scale.
Who labels? Surge AI, an expert-contractor labeling marketplace with substantive subject-matter knowledge in legal, medical, code, math, and alignment. Plus internal alignment researchers and in-house red teams.
How fast does it change? Across the Claude 2, 3, and 4 families, the major-refresh cadence stayed closer to weeks than quarters. Cohere’s cadence in the same window was closer to semiannual flagship releases.
Which errors come first? The Responsible Scaling Policy, published September 2023 and updated through 2024 and 2025, defines capability thresholds and forces evaluation work that surfaces specific failure modes. ASL-3 was activated with Opus 4 in May 2025. Each evaluation campaign produces a continuous, externally visible measurement regime, which means failure modes get surfaced publicly and feed into Anthropic’s next round of training decisions. The function the RSP plays for Anthropic is structurally adjacent to the function Microsoft’s relevancy tests played for LookSmart: an externalized measurement regime whose output is a list of what to fix next.
Cohere’s GPU-in-a-closet architecture makes that kind of shared cross-customer failure list structurally harder to build. That’s not an oversight. It’s strategy. It’s the strategy that costs you the shared loop.
Four answers at Anthropic. Two at Cohere. Same era, same research lineage, different loop.
The boring-stack test
Pick one model that matters and answer:
1. Who defines “right”? If the answer is “the model,” you don’t have a standard.
2. How often does “right” change? If the answer is “quarterly,” your cadence is probably slower than the market.
3. Which errors drive the next data slice? If the answer is “whatever customers report,” you don’t have error-driven data work. You have support.
4. Who applies the standard at scale? If the answer is “general annotators,” don’t pretend you have domain expertise.
Each of the four questions, on its own, is unremarkable. None requires a research breakthrough. None is hard to understand. The thing that’s hard is answering all four at once, inside the small window where compounding starts to mean something, while a competitor with the same talent and the same capital is choosing to answer one or two and call that strategy.
Andrew Ng named the discipline in 2021. The companies that compounded had been running it for twenty-two years already..
Companies referenced in this chapter
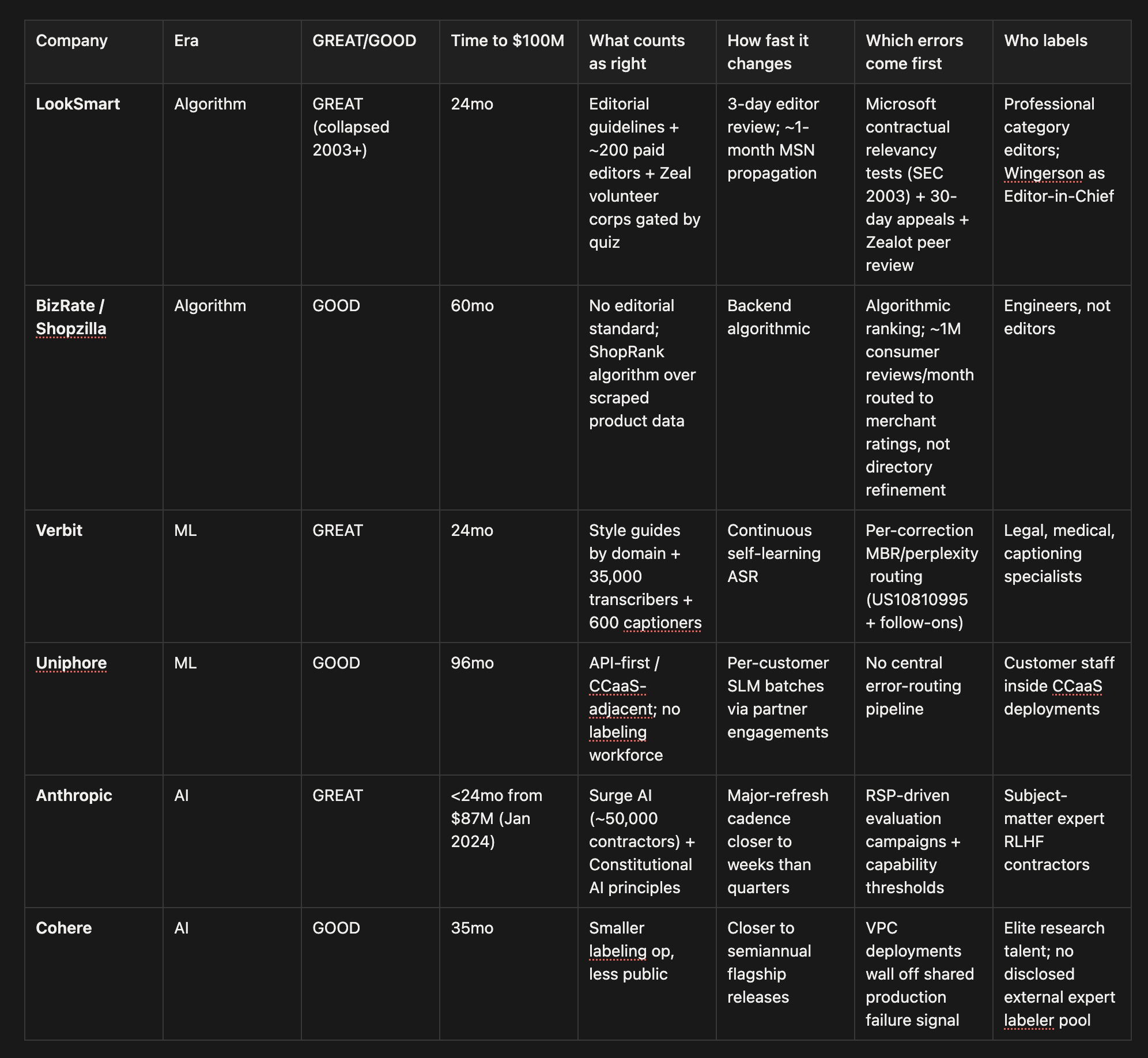
Chapter 6: The Distance from Data to Money
Why the fastest companies are rediscovering a loop the internet winners already knew.
“The price is what you pay. Value is what you get.” — Warren Buffett
“To live effectively is to live with adequate information.” — Norbert Wiener
On February 26, 1998, in a hotel ballroom in Monterey, California, a chunk of the TED audience hissed at a man named Bill Gross.
Gross had just demoed GoTo.com, the first commercial paid-search engine. The room hated it because it looked like corruption: people buying their way into search results. Gross’s collaborator Jeffrey Brewer described the objection: “the major objection people had was search should be egalitarian and fair. This is somehow polluting it. People being able to buy their way into search results is just wrong.”
Three of the people in that ballroom would prove the room wrong. Jeff Bezos was there. He’d internalize the architecture inside Amazon’s product page. Sergey Brin and Larry Page were also there, eight months from publishing the Stanford paper that would found Google. In Appendix A of that paper, they predicted on the record that ad-funded search engines would be inherently biased toward advertisers and away from users. Four years later, they shipped exactly the architecture they had predicted would be biased.
The room that hissed at Bill Gross included the founders of three of the largest internet companies that would ever exist, two of whom would explicitly build what they had publicly hissed at.
They saw pricing. They missed architecture.
This chapter is not really about pricing. Subscription, usage, auction, referral, CPM, enterprise license. Those are billing wrappers. The architectural variable underneath is proximity: how close the model decision sits to money, and how close the next user action sits to a training label that itself carries economic meaning.
The thesis in one sentence: every user action immediately following a model decision must be either money, or a label that points at money. If it’s neither, the loop is open.
An economic label is not just “the user clicked.” It is a user action that tells you something about value: money paid, time saved, risk reduced, work accepted, deal advanced, compute earned. The behavioral signal is whether the user did the thing. The economic label is what the thing was worth.
I’ll call the open loop a kitchen. A kitchen is anything that sits between the model decision and the economic label: humans on a sales process, batch attribution reports, redirects to a partner’s surface, weekly retraining cycles, contractual no-training clauses, off-platform inference, enterprise privacy boundaries. Kitchens slow the loop. The companies that compounded in this study spent thirty years finding ways to remove the kitchen, on one surface, in one architecture.
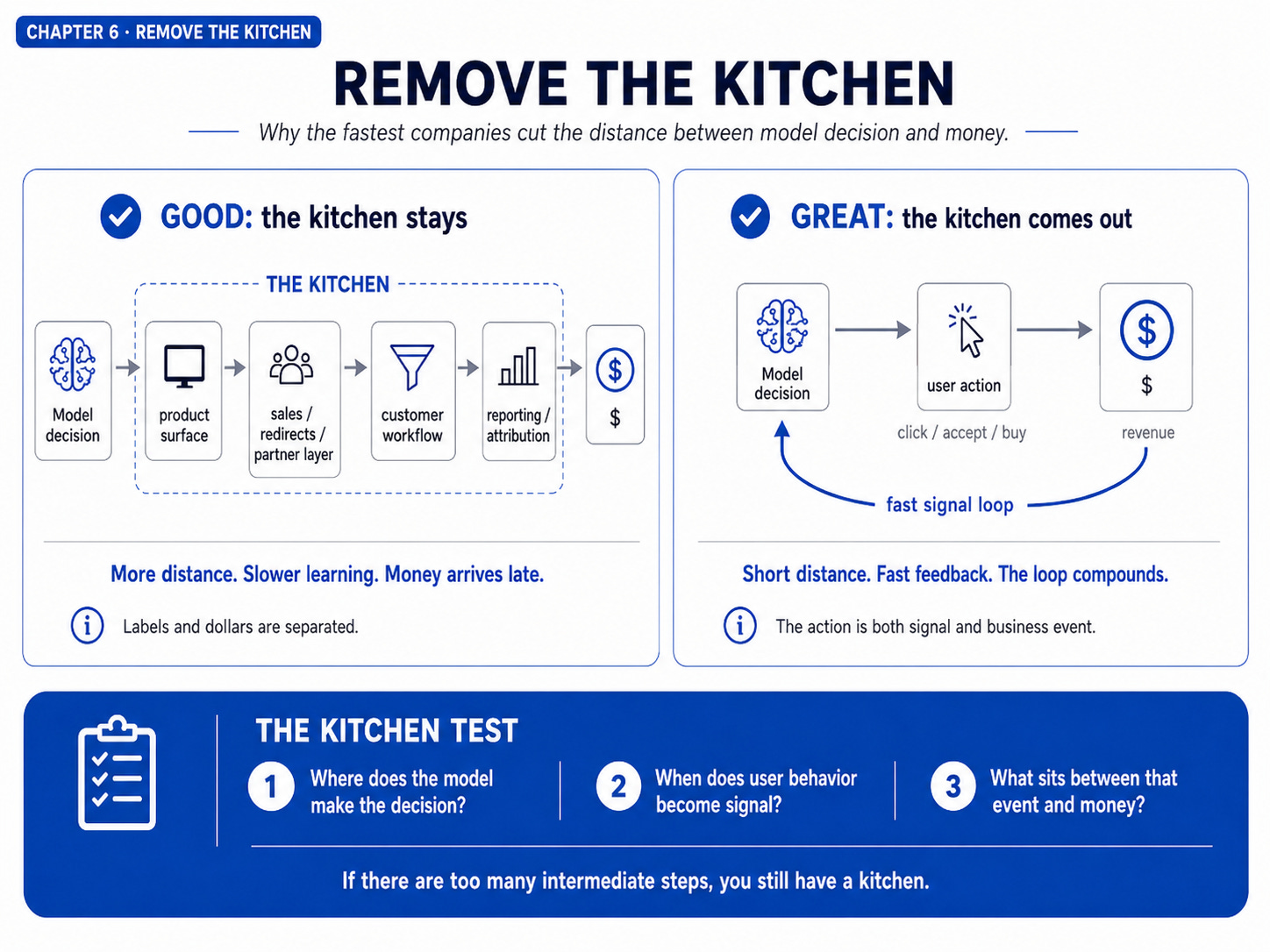
1. The click was the cash register
Brewer described what GoTo actually was: “all we had was one box. On the page, no advertisements on the front page, no other content, no news or other editorial. It was just a search box.” When you typed a query, paid listings appeared, ranked by bid. When you clicked one, two things happened immediately: the advertiser was billed, and GoTo collected revenue.
Crude? Yes. But architecturally important. The click was not yet Google’s relevance-ranked training signal. It was a priced performance signal. If an advertiser bought the wrong query, the mistake showed up in their wallet. If the traffic converted, they bid more. If it didn’t, they stopped paying. Relevance was not fully automated yet, but economic reality had entered the loop.
That was Gross’s breakthrough. Not a clever pricing trick. A shorter distance between search intent, user action, and money. GoTo made the click the cash register. Google’s later move was to make that same click part of the ranking machine.
GoTo went live June 1998. Revenue 1997: $22,000. Revenue 2000: $103M. Yahoo bought the company, by then renamed Overture, for $1.63B in October 2003.
DoubleClick ran the display-ad version of the loop. DART was not an auction in the GoTo sense; it was ad-serving, targeting, tracking, and reporting infrastructure. When DoubleClick served an ad, it could record the impression, read or set the user cookie, target future ads, and measure campaign performance across the network. Not bid-label-dollar in one event. But far closer to the money than the old media-buying kitchen.
The matched pair to Overture is Skyscanner.
Founded in Edinburgh in 2003, Skyscanner did flight search. Same broad user intent: a person looking for a thing. The architecture was different. Skyscanner aggregated airline fare data and presented options. When you clicked the option you wanted, you were redirected to the airline’s own site to actually book. The booking happened on the airline’s surface. The airline paid Skyscanner a referral fee, weeks later, after attribution.
Skyscanner’s own “How Skyscanner Works” page made the architecture explicit: “Skyscanner is not a travel agent. … When you click on a travel option, you will be redirected from our website and will then deal directly with the relevant travel provider.” Founder Gareth Williams, on stage at Skift Forum Europe in February 2017, made a sharper admission. Talking about Skyscanner’s then-new Direct Book program: “By offering a more seamless booking process with as little friction as possible, our direct book partners have experienced significant uplifts in both their conversion and ancillary up-sell rates.”
Fourteen years after founding, the founder realizes direct bookings are a good thing.
The architectural diagnosis: Skyscanner’s algorithm ranks flight options. The data that would tell Skyscanner which ranking actually drove a booking arrives weeks later in a batch attribution report, post-redirect, post-airline-funnel, with attribution loss baked in. By the time the data lands, the user has flown the trip. The model cannot retrain on fresh data because the fresh data does not arrive fresh. There are kitchens at every step: the redirect, the booking flow, the airline’s attribution pipeline, the referral reconciliation cycle.
Overture did 125× revenue growth in twenty-four months. Skyscanner did 180× over nine years. Same broad intent. Fundamentally different architecture.
2. Subscription works when the label still points at money
Here is the puzzle. Two of the cleanest data flywheels in the modern dataset (Cursor and Midjourney) both charge(d) subscription pricing. The user pays a flat monthly or annual amount and uses the product as much (until they hit a limit) as they want. By a strict reading of the Overture model, both should fail.
They don’t. They scale faster than any of their matched pairs.
The resolution: not every label is equal. A click, an accepted code suggestion, a preference ranking, a closed-won deal. These are not just behavioral traces. They are economic labels. They tell the system something about value, not merely taste. The subscription wrapper does not matter if the label underneath carries economic meaning.
Cursor. On September 12, 2025, Cursor’s engineering team published a blog post called “Online RL for the Cursor Tab Model.“ It contained the reward function: “We could assign a reward of 0.75 for accepted suggestions, a reward of -0.25 for rejected suggestions, and a reward of 0 if no suggestion is shown. … Currently, it takes us 1.5 to 2 hours to roll out a checkpoint and collect the data for the next step.” Four hundred million tab requests per day. New checkpoint every 90 to 120 minutes.
Every keystroke trained the next model. Every two hours the model went live. That’s not a flywheel. That’s a fire hose.
The accept/reject is an economic label because the developer is, in the act of accepting or rejecting, telling Cursor whether the suggestion was worth the cognitive cost of reading. The accept of a working completion saves time the developer is paid for. The reject of a broken completion saves time the developer would have wasted debugging. Each event has measurable economic content in the user’s own production minutes. The label is behavioral on its surface and economic underneath.
Three months earlier, in June 2025, Cursor had also moved the revenue side closer to compute reality. Pro stopped being priced around request counts and started including dollar-denominated frontier-model usage at API rates, with higher tiers for heavier users. The users producing the most accept/reject signal were now also financing the most inference. Nobody else in the AI era did that on purpose.
Midjourney. On April 4, 2025, the day after V7 launched, a paying Midjourney subscriber opened the app to generate images and was shown two hundred image pairs to rate before the model would respond to a single prompt. To use the new model, every user had to sit through approximately 200 forced image-pair preference ratings, building what Midjourney called a personalization profile. On June 17, 2025, V7 with personalization became default for every user.
Separately, Midjourney maintained a page at midjourney.com/rank where existing subscribers can rate image pairs to earn Fast GPU hours. Labeling labor literally exchanges for compute.
Midjourney’s preference label is not a dollar outcome. But it is economically priced inside the product: capability access and Fast GPU hours are exchanged for ranking labor. Revenue is pooled into the monthly tier. The label is metered, gated, and rate-limited.
Gong is the enterprise version of the same pattern. Chapter 3 covered why Gong named the axis at the CRO instead of the conversation surface. The proximity read is the architectural layer underneath: the seller’s behavioral response to Monday’s deal-health score lands later as closed-won or closed-lost dollars in the customer’s Salesforce. Those dollars retrain the model. Pooled subscription revenue. Economic labels inside the customer’s own system.
Grammarly is the negative case. Chapter 3 treated Grammarly as a buyer-axis mistake: it named the game as “writing goals” instead of communication outcomes. The proximity layer is the same failure one level lower. Grammarly captures behavioral labels everywhere — accept, reject, type, send. It does not capture the economic outcome of the writing: reply, interview, meeting booked, proposal accepted, deal closed. The integration access exists. Grammarly chose not to instrument it.
Grammarly did not lack data. It lacked an economic label.
3. Adding surfaces multiplies the kitchen
Grammarly built one surface with a kitchen baked in. Some companies build five surfaces, each with its own.
One surface, one loop. Each new surface adds its own kitchens.
In September 2001, Robin Li made a decision at Baidu that violates everything you’d write in a board deck. Baidu had been a profitable B2B business, licensing search technology to Chinese portals like Sohu and Sina. Portal licensing was 45.5% of revenue in 2002. Li walked away from it. He pivoted Baidu to a consumer search engine, ran the Overture-style PPC auction on Chinese-language queries, and let the licensing revenue collapse. By 2004, portal licensing was 2.2% of revenue. Paid search was 91%.
Side Note: Baidu’s founder Li also invented one of the first advanced search technologies for websites using hyperlinks, a result that was later cited by Sergey and Brin (not in the original paper but in their patent application).
The decision wasn’t strategic diversification. It was architectural concentration. Portal licensing required humans negotiating deals quarterly. Paid search ran the auction architecture in milliseconds. Li chose the surface with no kitchen and let the surface with kitchens go.
Excite ran the opposite play. Founded 1994 by six Stanford grads, IPO’d April 1996. Inside the scaling window, Excite added a portal, “My Excite Channel” merchandising, community features, banner advertising sold by humans for months at a time, and a $6.7B @Home cable broadband merger in January 1999. CEO George Bell, years later: “we all fell victim to the idea that we were going to be the mall and the one-stop shop for all of your application needs on the web; and that we would be able to monetize any and all those through advertising.”
Five surfaces. Five kitchens. By September 2001, Excite was in Chapter 11.
The same pattern shows up in the AI-era pairs in slightly different costumes. Cohere meters per token. Harvey charges enterprise license fees. Mistral has API revenue from its closed frontier models. None of those pricing models is what’s actually doing the work. Cohere’s customer-VPC architecture means corrections never leave the customer’s environment. Harvey’s Platform Agreement §10.8 commits the company in writing: “No Training. Harvey will not train any AI models using Your Content or Customer Data.” Mistral’s open-weights distribution means most of the inference happens off Mistral’s surface entirely. Each is a different mechanism for building a kitchen. The subscription, the per-token meter, the enterprise license, the open-weights torrent. Those are just what got billed.
This is the architectural layer underneath the previous two chapters. Disposition shows up as architecture. Architecture either closes the loop or builds the kitchen.
4. The proximity test
Pick one model/algorithm/AI decision your product makes all day long. Now answer:
1. What is the next user action after the model decision? Click, accept, reject, edit, book, buy, reply, close, churn?
2. Does that action carry economic meaning? Not engagement. Not activity. Money, saved time, reduced risk, won deals, retained users. Something the customer already pays to improve or avoid losing.
3. How long until that action becomes a training label? Milliseconds? Hours? Weeks? Never? If the answer is “weeks” or worse, the model is retraining on stale signal. Your competitor with hourly checkpoints is not.
4. Where is the kitchen? A redirect, a human sales process, a batch attribution report, an enterprise privacy boundary, an off-platform deployment, a no-training clause?
If you cannot point to the kitchen, you probably live inside it.
The companies that compounded spent thirty years removing the kitchen. They didn’t all do it by making every click a dollar. Half of them did it by making sure every click was a label pointing at a dollar.
Pricing is wrapping paper. The loop is the business.
Companies referenced in this chapter
So what?
Eight weeks. 100+ hours. Four books I won’t recommend. 23 pairs. 46 companies. One question.
The answer is what I told you on page one. The 15,000 words in between are why I believe it now: the GREATs weren’t smarter than the GOODs, weren’t better-funded, weren’t first. In half the pairs in this study, the GOOD was first to market, better-funded, better-credentialed, and still ended up at a fraction of the valuation. Sometimes a fraction of a fraction.
The GREATs shipped weird things and kept going. The GOODs reasoned themselves carefully into the wrong answer, with articulate, defensible reasons, every step of the way.
The GREATs did the locally absurd thing anyway. Not because they were braver or wiser. Because they could tolerate the mess long enough for the loop to start compounding.
So here is the last test.
Which chapter did you most want to argue with?
Start there. The thing you most want to reject is probably the discipline you would most reason yourself out of when it counts.
That is where the GOODs lost. Not where they were stupid.